Computer Vision Toolbox provides algorithms and apps for designing and testing computer vision systems. You can perform visual inspection, object detection and tracking, as well as feature detection, extraction, and matching. You can automate calibration workflows for single, stereo, and fisheye cameras. For 3D vision, the toolbox supports stereo vision, point cloud processing, structure from motion, and real-time visual and point cloud SLAM. Computer vision apps enable team-based ground truth labeling with automation, as well as camera calibration.
You can use pretrained object detectors or train custom detectors using deep learning and machine learning algorithms such as YOLO, SSD, and ACF. For semantic and instance segmentation, you can use deep learning algorithms such as U-Net, SOLO, and Mask R-CNN. You can perform image classification using vision transformers such as ViT. Pretrained models let you detect faces and pedestrians, perform optical character recognition (OCR), and recognize other common objects.
You can accelerate your algorithms by running them on multicore processors and GPUs. Toolbox algorithms support C/C++ code generation for integrating with existing code, desktop prototyping, and embedded vision system deployment.

Image and Video Ground Truth Labeling
Automate labeling for object detection, semantic segmentation, instance segmentation, and scene classification using the Video Labeler and Image Labeler apps.

Deep Learning and Machine Learning
Train machine learning models and deep learning networks—or use pretrained networks—for object detection and segmentation. Evaluate the performance of these networks and deploy them by generating C/C++ or CUDA® code.

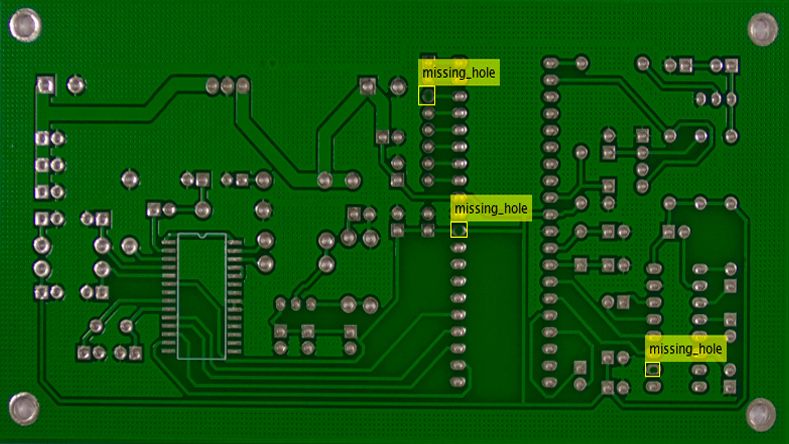
Automated Visual Inspection
Use the Automated Visual Inspection Library to automatically identify anomalies or defects as part of a manufacturing quality assurance process.

Camera Calibration
Estimate the intrinsic, extrinsic, and lens-distortion parameters of monocular and stereo cameras using the Camera Calibrator and Stereo Camera Calibrator apps.

Visual SLAM and 3D Vision
Extract the 3D structure of a scene from multiple 2D views. Estimate camera position and orientation with respect to its surroundings. Refine pose estimates using bundle adjustment and pose graph optimization.
Lidar and 3D Point Cloud Processing
Segment, cluster, downsample, denoise, register, and fit geometrical shapes with lidar or 3D point cloud data. Lidar Toolbox provides additional functionality to design, analyze, and test lidar processing systems.

Feature Detection, Extraction, and Matching
Detect, extract, and match features such as blobs, edges, and corners, across multiple images. Use the matched features for registration, object classification, or in complex workflows such as SLAM.

Multi-Object Tracking and Motion Estimation
Estimate motion and track multiple objects in video and image sequences.
Code Generation and Third-Party Support
Generate code from your computer vision algorithms for rapid prototyping, deployment, and verification. Integrate OpenCV-based projects and functions into MATLAB and Simulink.
Product Resources:

“We can access machine learning capabilities with a few lines of MATLAB code. Then, using code generation, engineers can deploy their trained classifier into the machine without manual intervention or delays in the process.”
Larry Mianzo, Caterpillar
Get a Free Trial
30 days of exploration at your fingertips.
Ready to Buy?
Get pricing information and explore related products.
Are You a Student?
Your school may already provide access to MATLAB, Simulink, and add-on products through a campus-wide license.
What's Next?



You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)
Asia Pacific
- Australia (English)
- India (English)
- New Zealand (English)
- 中国
- 日本Japanese (日本語)
- 한국Korean (한국어)