Accelerating Model-Based Design Through Continuous Integration
Jason Stallard, Cummins
Continuous integration (CI) is an agile methodology in which developers regularly submit and merge their source code changes into a central repository, which are then automatically built, tested, and released. CI plays a critical part in automating key parts of the Model-Based Design workflow, including verification, code generation, and testing. This approach enables developers to focus on developing new features, not on verifying features have been integrated correctly. Cummins and MathWorks developed a custom CI toolbox using object-oriented programming in MATLAB® and a production Jenkins® build automation server to automate Cummins’s entire Model-Based Design process including verifying AUTOSAR ARXML changes, checking compliance with industry modeling standards and guidelines, verifying requirements and coverage of model-in-the-loop and software-in-the-loop, performing design error detection using Simulink Design Verifier™, ensuring successful code generation, and proving the absence of critical run-time errors and applying industry code standard checking using Polyspace Bug Finder™ and Polyspace Code Prover™.
Published: 22 May 2023
Hello, everyone. So we were at the Automotive Conference. Is there anybody here who has not heard of Cummins? So if that's the case, then I need to talk to marketing. But speaking of marketing, I did borrow a couple of slides, so we'll go through the gratuitous marketing.
Cummins is a global company operating in 190 countries and territories with over 73,000 global employees. And we've been in business for 104 years now. And last year, we spent $1.2 billion in research and development.
So what does Cummins do? Cummins provides power solutions in a number of applications with a bunch of power offerings, including light, medium, and heavy-duty, mining, rail, bus. In recent years, we've been focusing on alternative energy sources such as electrification and hydrogen fuel cells.
One thing they all have in common is that there's software in every single one of them. And I'd like to take a common automotive example when we're talking about software and that's the cruise control. There is a cruise control in almost every single one of these applications, and that would be an important point I'll bring up later.
So some of our history and our journey between MBD and continuous integration. Cummins has [INAUDIBLE] controls for a little over 30 years, and we've been doing MBD about that long as well. We started in the early days with MATLAB 6.1 using the Beacon Auto Coder. And while it allowed us to generate code from our source models, we had difficulty with it because we couldn't simulate those models, primarily because we have a software-centric design and architecture.
Moving on to our 2006 [INAUDIBLE] and adopting the Real-Time Workshop Embedded Coder, we were a solid MathWorks shop at that time, but we were still reliant on that same software architecture, so our source model still couldn't simulate without effort.
And it's at that time that we approached the MathWorks consulting team to find ways that we can make those source models simulate. And we came up with a platform that we call the [? Marline ?] Architecture for Component Integration or MArCI. And that enabled us to simulate our controls models, but it wasn't without its own problems.
Primarily, our simulation performance was underwhelming, and we often incurred software build times over 10 hours because we were relying on system-level cogen for system-level models that didn't perform well. And again, we reached out to the consulting team and said, we've got to fix this.
And with their help, we engaged it in a process assessment with two primary outcomes being that we needed to embrace a different software architecture, namely [? AutoStar, ?] and fully embrace simulation-based product development.
So I harped a little bit about the software architecture and that's really based on product line, which is component-based software and model-based designs, and it really implies a lot of reuse enabling products' specific behaviors, and you think back to my example with the cruise control.
So when you have that cruise control used across so many applications with different behaviors, how do you effectively test that and take it to the next level? If I have thousands of components across tens and hundreds of products, how do I test them? I'm going to have nearly infinite configurability and infinitely large data sets. No team could accomplish that without the use of CI.
So for Cummins, Continuous Integration System benefits us through scalability given the breadth of our applications. It allows us to ensure consistency of the applications tools and workflows across all of our teams. It offloads some of the time-consuming tasks, but not without prequalifying the ability to run those things locally.
And increases our velocity of innovation. And we have a truly global software factory. Management is able to obtain visibility as to the status and effectiveness of the Continuous Integration System, and we're able to coordinate and trial integrations on-demand, but never off the clock.
So when adopting a Continuous Integration System, there is a number of obstacles that you have to consider before you do it. First and foremost is the culture of the development, organization, and workflows. They have to adapt to embrace CI. You can't make CI adapt to what you have already.
The business also has to be able to invest in CI, and I can tell you in our journey, adopting CI, it's been a lot of conversations about the expense of standing up servers and redesigning and implementing. But as a part of that, you also have careful planning of your pipeline so that they're codified to best practices.
And you also need to consider the who, what, where, and how to get started when you're doing that implementation. And it was with that that we turned again the Consulting Team to help stand it up for our MBD pipelines.
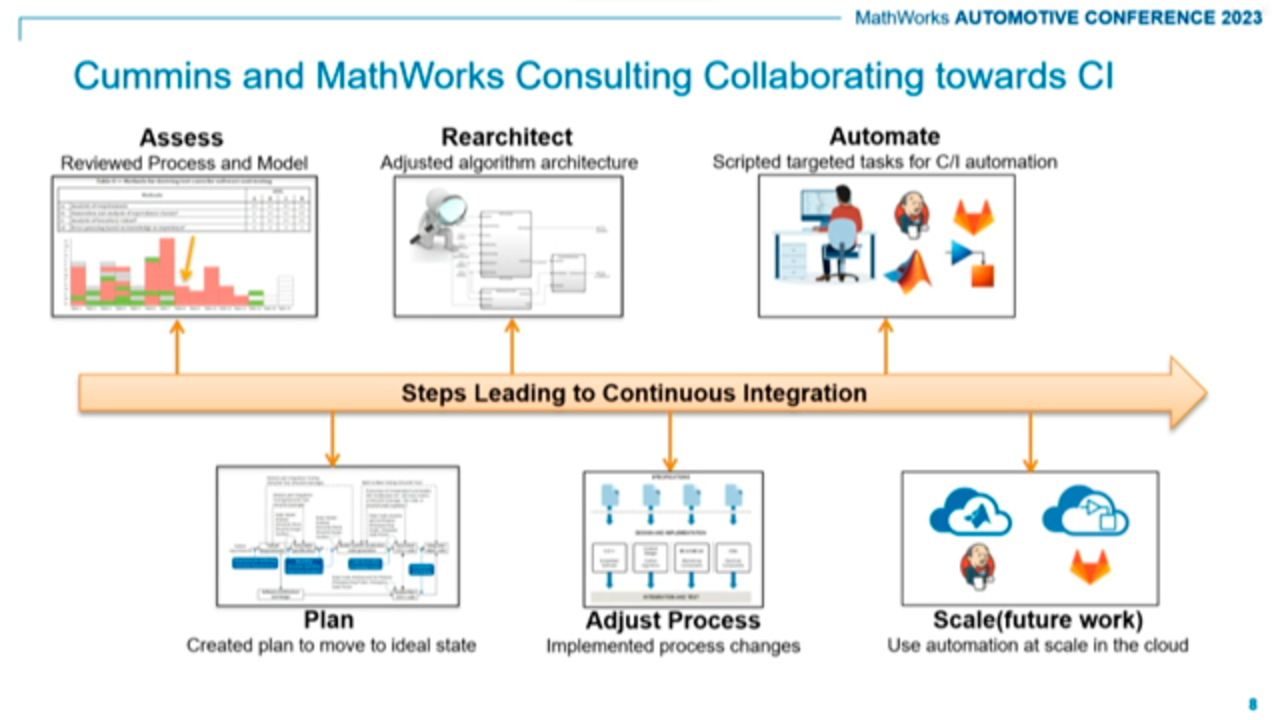
As Jason's mentioned, we got a closer relationship with Cummins around 2018 where we came in as a consulting organization and did a process assessment, and that's where we just tried to say, OK, we're going to ask you lots of difficult questions about the way you do business and we want you to open all the doors to the closets and make sure that we see everything that's going on in a spirit of trying to improve and optimize the processes that they had in place.
So after looking at that assessment and finding the areas that we've seen talking with lots of customers over the decades about what would be best practices to implement their processes, we came up with a plan together and then embarked on a journey to re-architect the way that components were defined in order to facilitate their integration into the software architecture, as well as to improve the ability to do model in-the-loop-type simulations on desktops.
That process was adjusted, changes were implemented, and then finally, we got to close to today, just a year or two ago, where we said, OK, well now we're ready to scale these activities which are ready for automation up into the server side so that people can take advantage of having more of the machinery and more of the automation do their job.
Not that we don't all like to hit Control-D and update your model and then go get coffee and lunch and whatever when that takes hours, but we're trying to get away from that kind of need on a regular basis.
And in the future, we're looking forward to how do we take the scalability from local server instances but talk about EC2 to level or Azure Web Services in order to expand the capability and have more of an elastic compute platform when things are needed on-demand.
OK, so let's talk a little bit about how to implement a system like this. So you know here's a typical workflow. We have a developer and she stages some commit and pushes those changes into a repo, and then now-- and again, after prequalification locally, but she's got a high confidence that she's not introducing more churn into the overall mechanisms.
And then there's a Jenkins instance which has local workers on a server, and those are going to fetch the repository. If you look down along the bottom of the screen here, we'll talk about what the details are, what happens in the pipeline.
So after the build is triggered, we do a Git checkout, you validate the project. So let's make sure that all the files are where we think they should be and the, test cases exist, the model updates the basics of, is this actually configured appropriately for CI? And if it's not, then we fail that. Somebody can look at the job status quickly and say, OK, well now I need to go make some improvements so that I check this in next time.
And then there's a series of stages where there's an ARXML import and update that's applied to the model interface. What that allows Cummins to do is verify that the interface is still compatible with the architecture that was specified by the software architects using the authoring tools.
Then the Model Advisor is applied, and there's a variety of model checks that are MathWorks built-in checks, MAB checks, and Cummins' own checks that they've authored in order to enforce common modeling style and have patterns that are supportive and accurate within their software architecture.
And then there'll be a series of unit tests that are run, and those are automated and iterated through, collect the results, collect the model coverage, generate the reports as artifacts that you keep. And then there's a design verification stage where you can use a design verifier to find out are there any obvious flaws in the implementation? Is there unreachable things in the code? Are there divide by 0's that we're going to want to catch before we get into runtime?
And then code generation, which is then shipped off to Polyspace, Code Approver, and Bug Finder in order to do abstract interpretation and formal verification of the generated code. And I've drawn a box around the pieces in the middle there because those are all things that they have no constraints upon one another, so they can be done in parallel.
So if you have multiple workers on your server, you can just chunk those out into different things. And of course, you can parallelize this whole pipeline when you have multiple different components that need to be qualified. That's easy. That's the embarrassing kind of parallelization because they're really not dependent.
That all wraps up. We archive the artifacts and push that into a SharePoint repository, update the dashboard and Teams, and then people like Jason can get a good overview of what's the overall health status of our software factory and are there some issues that we need to look at or what groups do we need to help come up the learning curve and make sure that their models are compliant with Model Advisor, for example.
OK, so here's an example of what the Job Status dashboard looks like. So here's the plain Jenkins interface. And you can see what I've highlighted there. I think I have a laser. Yeah, so I've highlighted this one row in the report, and that gives you the overall job status. I picked a good one. Because it's all green.
But what I can do, then, is drill into any one of those squares and say, OK, well, what's going on in the Model Advisor pipeline? And that brings me up a dashboard which has more detailed results, and then I can expand that dashboard once again and look at we're getting closer to things that are-- the built-in dashboard capabilities that we have in Simulink now.
Similarly, you can take this in the other direction and roll up that job status into a series of component statuses, and then that can give you something to look at for the whole project or a whole product line, and we're still in the process of setting up all those different slices and views, but once we have this fundamental capability to create these jobs, then we're going to want to summarize the status in different ways that are helpful for the overall goals of the business.
So I mentioned very briefly that we were thinking about the scalability of the service. So right now, we're at the stage where we've got local CI. We've got VMs and we've got a local Jenkins servers, and that's just supporting the organization. But as more and more people are opting into this, there's a lot of interest in taking these things and package them into Docker containers. We're looking at Kubernetes and other technologies now in order to do load balancing for a server farm.
And you have different choices. These things are all within our capabilities now, within our tools, but you can look at either cloud CI with local agents. So if you want to have GitHub actions and then have things run locally, that's one architectural approach. There are other things where you look at your leasing agents from organizations like Amazon or Azure Cloud, and there's pros and cons to those.
And if you want the full cloud-based installation, you don't have to worry about-- you want more compute resource, you just ask for more and you get more, and then you get a check at the end-- or a bill at the end of the month that says, OK, well here's the resources you use, you're leasing them, enjoy. If you want to continue using it, then you'll need to pay your bill.
The disadvantage to that is that your IP has to go to where their resources are. And so there's this interplay of organizationally do you want to hang on to things inside your walls? You may want to establish your own cloud services that are on-premise. You may want to use off-premise, you may want to install on local servers. And there's pros and cons with everything, but this is just a little bit of a background and what those thought processes might be to make that kind of a decision.
So to summarize, there are a lot of benefits to using CI for improving engineering productivity. You're reducing the overhead at the desktop with automation. You're building consistency in the teams. If some team is trying to submit things and all their jobs fail, well-- now suddenly, there's a lot of attention that they're maybe not working in the same way that other groups have been working in the organization, and now that attention can lead to the right emphasis on the importance of that consistency.
You can now have more simulation capability and enable a cultural shift to early verification because now you're being asked to make some test cases. Well, if you-- now you maybe thinking about for the first time, what would my test cases be? What does it mean to have unit verification on this component that I'm working on?
And so starting that conversation is an important way to have your organization perhaps grow into doing more with the simulation environment itself. And then finally, you can collaborate. You have other teams that in the past, your work may not have gotten together until it's flashed on a controller and in a vehicle on a test. And now, you can start to see the overall impact of the way your algorithm changes are starting to change the behavior of the systems that you're working on.
And then as Jason mentioned, it's key to enabling a product line approach at scale because, again, just the breadth of application areas and ways you may want to reuse your algorithms, it can be disastrous to try to imagine you can go test that in a traditional and the physical kind of way.
And then finally, I'll mention that we are supporting our native support in this area. While this was a consulting project and it was effort for sure to get all these things implemented and working smoothly, our native support is going to be more talked about by my colleague Bernard who will be talking a little bit more this afternoon.
And essentially, from last year, we offer a CI support package which streamlines the process of only-- of not only developing what your model VNB and code VNB process is going to be, but also expressing that in a way that you can generate a pipeline script for it and then import that into tools like Jenkins with less customization and learning curve than was required in the past. OK. And that's the last slide, so thanks. Thanks for your attention.
[APPLAUSE]
Up Next:


Related Videos:








Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: United States.
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)