Cell Array, Table, Timetable, Struct, or Dictionary? Choosing a Container Type
What do you do when you need to work with data that combines numbers, strings, datetimes, categoricals, and other types of data? Container types such as a cell array, table, timetable, struct, and dictionary can store heterogeneous data, but how do you choose the right one for your application? The choice of container type can have a big impact on your productivity and the performance of your code. Learn about the five major container types in MATLAB® , how they represent data, and the advantages and disadvantages of each.
Published: 3 May 2023
Hello, everyone, and welcome. My name is David Garrison. I'm the product manager for the MATLAB language.
Hello, everyone. My name is Francesca Marini. I am also MATLAB product manager, and I focus on the MATLAB Desktop and Editor. We are here today to talk about MATLAB container types for storing and working with heterogeneous data.
So when you have heterogeneous data, there are multiple ways you can store it in MATLAB. Now, it might not always be obvious which one is the best. We'll walk through a few examples to compare and contrast, give you a better idea of how to choose the right one. So let's start with the oldest way in MATLAB to store heterogeneous-type data, and that's the cell array.
So many of you have worked with cell arrays. So we'll just briefly review what a cell array is. So a cell array's a data type, which has individual containers called cells. And each one of those cells can contain any type of data. For example, I might create a 2-by-3 cell array which contains different types of data. In this example, the first row has a numeric array. It has a string, and it has a 5-by-1 array of line objects.
The second row is a date time followed by a function handle followed by another cell array. So I can store cell arrays inside of cell arrays. So if I want to index into a cell array, I can do that the same way as I do for any other MATLAB array. I use the parentheses. So I might, for example, ask for the first row of my cell array. Or maybe I ask for the second column.
If I want the contents of one of those cells, I use curly braces. And in this case, the contents of the cell in row 2 column 2 is a function handle. And I can show that that's true just by calling it with pi/2. So cell arrays can contain anything. In that respect, they are the most generic and flexible container types that we'll talk about today. However, a cell array might not be the fastest or most convenient way to work through data. So Francesca, what other options do people have to work with heterogeneous data?
Well, Dave, there's the table data type. This is great when you have column-oriented or tabular data. You probably have a lot of data in text files or spreadsheets. Each variable in a table can have a different type and a different size. There's only one very important restriction, that each variable in the table must have the same number of rows. Let me show you an example.
I can use the function read table to read spreadsheet files. And this function creates a table with a variable for each column in the file and reads the variable name from the first row of the file. I'm loading now a data set that contains storm event data in various locations of the United States. And I will be converting the variable that I need to be categorical or date time.
Let's see how my table looks like. In this table, we can see the records of each storm event, its ID and type, the date and the state in which it happened, and the amount of damage created expressed dollars. We see that in the table we have variables that have different data types-- string, categorical, date time, and dollar.
There are multiple ways to access data in a table. If you're referencing to it like an object or struct using the dot notation, then you'll get an array as a key output, like in this example.
And I'll be using this also to quickly access the event type variable and plot through the work cloud function, the events with related frequency. This function requires the taxonomy code blocks.
If you reference a table as a matrix using parentheses, you'll be preserving the type of the variable you index to and you'll get a table as output, like in this case. And if a reference a table using curly braces you'll get a salary, and we will see this here. And finally, you can also use both the smooth parentheses to strike only selected rows and specify the column selecting variables by name.
The comment below would indeed create a table that has only the first 10 rows of the original table, and the event ID, and even type variables.
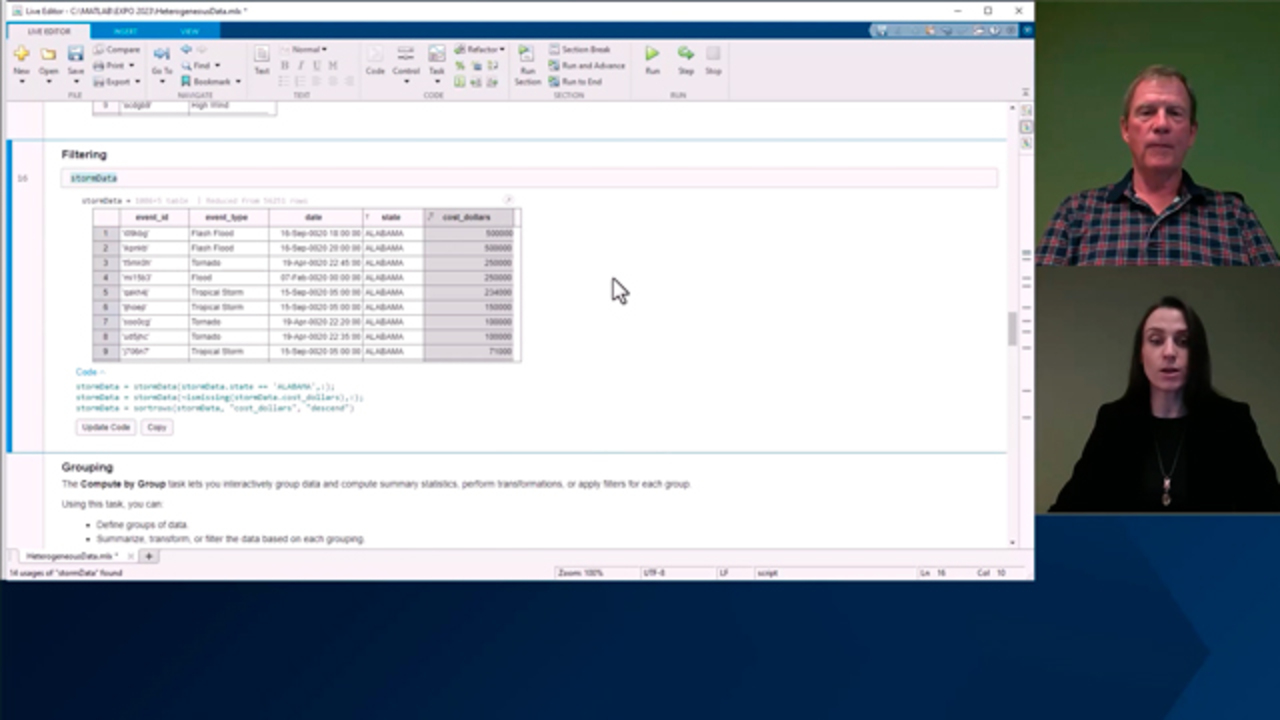
So Francesca, this table has a lot of data in it. What if I just want to see a subset of the data?
Of course, you can. With table, we have the possibility to apply filters to only show the intended values and variables. And you can interact directly in your table. I could, for example, show only the events in the state of Alabama, and MATLAB show the code for me. And now, let me also sort the damage column to see the events that caused the most expensive cost after removing those that have missing values. And we see that also in this case, MATLAB gives me back the code. And I can copy it and embed in my script for my convenience.
So what would happen if I wanted to compute some summary statistics for some of the values in the table?
I'm glad you asked. Indeed, when working with tables, it very often happens that you need to perform group calculation to interpret large data set. In such calculations, you use a grouping variable to split data set into groups and apply a function to each group. I want to group now, for instance, by event type and state, and evaluate the amount of damage in dollars in each group. I'm going to use a feature of the Live Editor that is called live task. And it is a small app embedded in my live script that can also generate code for me.
I can always choose to write the code myself. However, I like to use tasks in cases like this one to reduce development time and errors. Live tasks can be found here below the Live Editor Tools Suite tab. And there are, as you can see, a lot of tasks available. The one I'm interested in is the computer group in the preprocessing data section.
I love my live task. And I select the variables that I want to group by, event type and state, and then I want to compute the sum on the variable cost dollar. I get my output table where we see the total cost per event type for a state.
Impressive. Is there a way to combine two tables together?
I believe that it's happened to you as well when dealing with data set that you have to combine multiple sources of data, or tables, to get all the information you needed. In my case, for instance, the table I have does not tell me the location in which the event happened. And I need to rely on another table to store the latitude and longitude information for each event ID.
It is not convenient to work with two tables. And I used another live task to combine them. I'll just have to select the event ID as the emerging variable, and the type of joint to finally have a single table that includes all the needed information.
Wow. You can really do a lot with tables. But suppose my tabular data is time based. Is table a good choice for temporal data?
In this case, we have a more suitable container. For date time data, there this time table. Let's see an example. I have here two signals from two seismic stations. Each one has its sampling time and amplitude. And working with timetable, in this case, it's convenient because we have dedicated functions for them. In my case, the two signals have different sampling frequencies. And I can use the synchronized function to synchronize them.
I will take advantage of another live task dedicated to this. But as the two signals have different sampling rate, if we simply synchronize them as they are, as there fewer samples in the harp signal, this variable will contain lots of none. So we'll just have to choose intersection as the selected method. And I get to output my synchronized signals with the lower of the two sampling frequency.
For more complex cases, we could also specify the method for adjusting the data. And with timetables, I can take advantage of the stack plot function that plots the variables of a timetable in a stack plot. So now that we have seen two of the newer container types, table and timetable, let's go back in time. And can you Dave, review one of the older container types in MATLAB, the structure?
Sure, Francesca. So I think many of you know that structure store data and name fields, they are older-- one of the older types like cells. And like cells, the fields of a struct can store any kind of data. But with structure, you reference the data using the field name as opposed to using a numeric index.
So we'll take a simple example here. We'll create a struct to store some data about some stars. So we have a catalog number, we have a name, a constellation, and the magnitude of the star. And so we create that. And then, if we want to reference one of the value-- one of the pieces of information about this star, we simply use the field name. So we have structure, followed by the period, followed by the name of the field. And that gives us back the magnitude for this particular star.
So that was a simple example of a struct. Now, let's extend that to a larger data set. So suppose I have data on a list of bright stars. Originally, this set was originally published by Harvard University back in 1908. The first thing I could do is to read it into a table from a CSV file. But I want to store my data as a array of structs rather than as a table.
So I can use the struct table function to convert it. And once I do that, I now have an array of structs. There are 332 of them. And each one of them contains the information that's important to me about the star. So number 278 has information about Sirius. If I want to look up the star by a particular catalog number, I can do that as well using the array of structs. And so I just use logical indexing and I ask MATLAB to tell me, which one of the structs, or give me the information from the struct, whose catalog number is 2061.
And so I get the information there on the star Betelgeuse. Now, it's also possible to store all the data for the stars in a single struct instead of using an array of struct. And here, I'm going to do that because I'm going to show you something very interesting about arrays of structs versus scale of structs.
So I'm going to use the catalog numbers as field names. But keep in mind, those people who have used structs before, you know that a struct-- the field names in a struct have to be valid MATLAB identifiers. So they have to follow the same rules as we use for MATLAB variable names. But I can put them all together and I can use this HR prefix to create the name of the fields. And so now, I have a single struct with 332 fields. And each one of those fields contains another struct, which contains the rest of the information about each one of the stars.
And why would you want to store all the data in a single struct? Is there an advantage?
Yeah, there is a very important advantage to doing that. So I'm going to show you an example of the difference between storing the data as a struct array and storing the data as a scalar struct. And that difference is performance. And so if I-- if lookup speed is important to me, then I might want to consider using a scalar struct. Because in this first example that you see here, I'm actually looking up the star whose catalog number is 5735, just the way that I did it before, in an array of struct.
And in the second example, I'm going to look it up using the field name from a scalar struct. And when you run this code, you can see that the scalar struct is about 25 times faster than the array of struct for doing lookups. So lookups are faster than using a scalar struct. And a scalar struct is a good choice if you have a relatively small number of entries. Here, 332 is getting kind of a little bit large.
So a scalar struct may not be well suited if you have a large number of entries. So structs can be a great way to store your data. But keep in mind the limitations. First of all, struct field names have to be strings that are MATLAB-- that are valid MATLAB identifiers. Lookup and structive arrays can be slow, particularly if you have a large array. And then lookup in a scalar struct is faster. But a scalar struct may not be well suited for a large number of entries.
So Dave, is there a way to store a large number of entries and get good lookup performance?
Yes, Francesca. There is. And that brings us to MATLAB's newest container type called dictionary. Now dictionary is a data type that maps keys to values. You give your dictionary a key, and it gives you back the value. And dictionaries are optimized for fast lookup. And the lookup speed is independent of the number of entries in the dictionary, which is not true for arrays.
So let's create a small dictionary from our star catalog. This time, I'll just use the catalog number and the name of the star just for illustration here. I'm going to create-- this first command here uses the dictionary function with a set of key value pairs to create a dictionary with four entries in it.
So each entry in the dictionary has a key and a value. The important thing to remember about dictionaries is that the keys must be unique. Now, the values can be anything you want. But the keys have to be unique. But the keys do have to be-- and the keys have to be the same type, and the values have to be the same type.
If you want to add something to the dictionary, you can just simply use the dictionary name and index with the catalog number, and then do an assignment that's shown here. So now, my dictionary has six items in it. And if you want to look up something in the dictionary, you just use the name of the dictionary and the key.
So here, the entry for 890-- catalog number 897 is Acamar. If I then do an assignment to that element in the dictionary, it will replace the existing value. So now, my dictionary has changed so that Sirius is the first entry in the dictionary. Now, one of the big advantages of using dictionaries over structs is the fact that you can do vectorized operations, which is not something that you can do very easily with structs.
So if I want to look up three of the values in the dictionary using three keys, 897, 219, and 3572, I can do that in a single command. And I get back the three values that correspond to those three keys. I can use vectorized operations to do lookups, to do-- to add things to the dictionary, or to delete items from the dictionary.
The other advantage of dictionaries is that the keys and values can be any MATLAB type. Now the keys all have to be the same type and the values all have to be the same type. But you can use anything. Remember, we said with structs, the field names always have to be a valid MATLAB identifier. But that's not true with dictionaries. As you can see from the previous examples, we've been using integer values as our keys instead of using a identifier.
And then, of course, the values can be anything as well. So now, I'll do something a little more complicated and take all of the data for the stars that I'm interested in. And now, the catalog number is the key. And the value is all of that other information about each one of those stars. So if I look up the dictionary, if I use the dictionary key 2061 and I look up the value, then I get the data about the star Betelgeuse.
So now with dictionaries, you can use any types of keys, any types of values. The dictionaries are very flexible. And they have the property that you can very quickly do a lookup based on the key value. And I'll demonstrate that here in this last section. Again, the first bit of code here is doing the timing test for doing the lookup in an array of struct. And then the second bit of code here is doing a timing test for how long it takes to do the same lookup in a dictionary.
And again, like scalar structs versus struct arrays, dictionaries are much faster than trying to do this with an array of structs. So dictionaries provide lookup performance equal to that of scalar structs. But they provide additional advantages in that you can do vectorized lookup, assignment and deletion, and you can use dictionary keys and values that can be any MATLAB type.
OK, Dave. This was very interesting. So let's recap. You've shown me cell arrays that allow you to store all kinds of data and are probably the most flexible data type. But cell arrays may not give you the performance that you need.
Right. And you showed us that tables are optimized for tabular data, where each column can store a different kind of data. We saw that tables have a lot of specialized functions to help you manipulate your data in various ways, including filtering, grouping, and joining tables together. And we also saw that there was a special type of table called a timetable, which is optimized to work with daytime data.
We then looked back in time, and we saw how struct works, one of the oldest data type in MATLAB. You can store that in an array of struct or a scalar struct. Lookup in scalar struct is faster, but maybe hard to manage for a large set of data. The newest data type in MATLAB, the dictionary, allows you to store key and values of any time with fast lookup.
So the next time you have a heterogeneous set of data, think about the container types we talked about today and the advantages of each. For more information on the container types in MATLAB, and data types in general, see the MATLAB documentation at the link below.
Thanks to everyone for your time today.
Thanks very much. Bye-bye.
[AUDIO LOGO]
Featured Product
MATLAB










Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: United States.
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)