Master Class: Accelerating Development for Software-Defined Vehicles Using CI/CD
In this session, explore the application development and integration of reference workflows into a continuous integration (CI) and continuous delivery (CD) pipeline, and how to streamline the software development lifecycle with a Model-Based Design approach.
The key takeaways from this master class will be:
- Using model-based development for service-oriented architectures
- Setting up and automating Model-Based Design verification and validation using CI/CD
- Deploying software-defined vehicle applications
- Setting up a test automation framework for virtual simulation
Published: 8 Dec 2023
Which is called Master Class in Accelerating Development for Software Defined Vehicle Using CI CD. I have with me, two young dynamic application engineers-- senior application engineer from MathWorks, Vamshi Kumbham and Nukul Sehgal
Vamshi is a senior application engineer specialized in the area of modeling, simulation, automatic code generation, and verification and validation. He brings in experience of more than a decade. I also have with me Nukul Sehgal, again, a senior application engineer in MathWorks, and again, a decade years of experience working in a very different areas of system engineering, production code generation, functional safety of software, and cyber security.
I would like to invite them to the stage and then take you through the Master Class. Please give a big round of applause for them. Thank you.
[APPLAUSE]
Hi, everyone. Welcome back to the session. It must be much loaded sessions from the morning itself. And now we are going to have Master Class. So we'll keep it light, but something you can take away from this session. So we will talk about accelerating development for software-defined vehicles using CI CD. And for that, what you need to understand is what is software-defined vehicles.
So from the morning itself, we are talking about software-defined vehicles. And you might now-- whoever is new to this term, might already get an idea about what is actually a software-defined vehicle. It's a change that companies are going through-- the vehicle companies are going through, where software is more prominent than traditional electrical mechanical stuff. And the features and personalization is more driven by the software.
And to achieve that, the base of that is service-oriented architectures, which gives you a flexibility to update dynamic applications running on your new generation electronics and electrical architecture. So talking about that, as an OEM, you must have seen, we are moving towards centralization of computing where we are moving towards more centralized ECUs approach. We are moving from the distributed electronics control unit to a centralized computers.
Maybe you are in a journey of that. You must be working on [INAUDIBLE] domain control units right now. And then, ultimately, the goal is to have centralized computers.
To achieve that, we are having high performance CPUs, GPUs. And on top of that, we are running this new software architecture, which we call as service-oriented architectures. And that's where we talk about having more frequent updates, selective updates, and over-the-air. And in this talk, like I said before, we are going to talk about the modeling and the automation aspects of this applications. So modeling service-oriented architectures, and then bringing the agility to the development and making your development cycle more short.
So the smart cars call for smart ways of writing the code. And the model-based design is one of them. You build a software-defined vehicle with service-oriented architecture. And you can simulate with the models that can help you work at the right level of abstractions.
So here, we are talking about an architecture where we have more services based approach. And on the basis of request response, we can share the information. So we'll talk about from architecture to deployment of service-oriented applications, deploying it to the Linux targets and virtual ECUs on the cloud. And then my colleague, Vamshi, will take you through the DevOps and continuous integration and continuous deployment workflows.
So what is SOA all about? So SOA consists of services, which I said already, they can communicate across different platforms in your vehicle architecture that provides you more flexible approach to add, remove, or update, or modify any software applications during the runtime of the vehicles. And there are various industry standards through which we can implement these services. You must be already knowing about AUTOSAR Adaptive, DDS, or ROS, more prevalent in the industrial and robotics areas.
So how differentiates from the normal signal-oriented approach? It is based on the service-oriented communication. And the signal-oriented communication, we have broadcast-based messages where we are just throwing out the information on the bus, overloading it, and just everyone has to take it, whether they are consuming it or not.
So in signal-oriented communication, we have more data independent of our needs, which creates high bus loads and not efficient approach. In this service-oriented communication, it's more on the request response basis. And we can send data on the basis of the needs on the request, where we can request the other node or peer to send some data, and we'll get a response out of it. And in that case, we'll create an efficient way of communication, which will not load the bus. And it will give you an high throughput.
And today, we are going to talk about how we can describe the service-oriented architecture with System Composer, how you can implement the detailed design using Simulink, and then generate the code for Adaptive AUTOSAR using the Embedded Coder and AUTOSAR Blockset. So this is the workflow that we are going to talk about.
How many of you know about the System Composer tool here? Can I get some hand raises? We'll get a few ones. So System Composer isn't actually an architecture tool. You can use that to do a system architecture. You can use it for software architecture. And then you can target the middlewares, like AUTOSAR, using the AUTOSAR architectures.
Here, in this case, you see how intuitive this tool is, where we are just creating the components. The ports are dynamic. And just when we are connecting these, it creates service interfaces. And here, I'm showing you an application, which we are making as a lane guidance app. It uses detections app service to detect the lane. And then the detections app uses the services from the camera and the radar services.
So here, we have broken down this lane guidance app into, you see, four services, where the whole crux is in the lane guidance app. The detections app help detecting the lanes from the inputs that it is getting from the camera service and the radar service.
Once this architecture is established, what we need to do is we need to create some interfaces. So here, if you see, down there, we are creating some interfaces. And we select these interfaces and drag and drop on top of these ports that we have created. And once we set on one-- once we connect this interface to the ports, the other provider port will also reflect those interfaces. So you can see, I'm selecting the port. And it is getting highlighted down there in the interface sections.
So defining the interfaces are important. In service-oriented architecture, it gives you how the services are interacting with each other. It's one of the important factors where you create the boundaries of the services. What is service boundary? You need to understand that.
So let's suppose we have the camera. So camera has a boundary that everything related to the camera will be consolidated under one service, which is the camera service. So whichever applications needs to get the data from the camera service, they can just subscribe to this camera service. And they don't need to implement that camera service again and again. So that's how your service-oriented architecture provides a flexibility, reduce the load, and everything is dynamic.
Next, we need to define the stereotypes. Again, stereotypes are one of the way where you can provide the information related to your services. So here, if you see, I'm just providing some information, color coding those components. And this will give, again, boundaries information, and ensures that each service has clear and distinct responsibility, so kind of abstracted in nature.
Next to that, I can define the service behavior. So we all know Simulink here, right? Simulink, guys? More hand-raisers, I can expect. Yeah, obviously.
So what we can do is we can define the service behavior using Simulink. And in this case, if you see, you have options to right-click and just create the Simulink behavior or attach your already created Simulink model to this component. And once I select to create a Simulink behavior from this, you see all the service interface-related modeling is already established in those models.
And these models, if you see, contains the functions. And using the function editor, I can reorder them based on our execution. And then I can simulate it and log the events. Using Sequence Viewer, I can see the sequence, how the services are interacting with each other. So that's how easy it makes simulation of services and service-oriented architecture for you.
And with this, I just want to inform you that we have come across the new semantics for creating your services. I think you have already attended-- some of you might have attended the session from Shweta's talk, talking about the service-oriented architecture.
And I would definitely try to call out one of our customer, KPIT, who has used the service-oriented architecture for the implementation of arbitration of ADAS features. And here, you can see one of the application that they have made for ADAS. And then they are simulating these, logging the events, and using the Sequence Viewer. Just again, like what I have done, they have seen the sequence of calls between the different services.
The link to the talk is present in this slides. And after the proceedings are released, you can just visit this. And this is a cheat sheet, I would say, to go through those semantics, the new semantics that we have introduced for service-oriented architecture.
And we talk about send and receive. We talk about publish, subscribe, polling-based subscription, event-driven, and then the RPCs, synchronous, asynchronous, and server base-- server implementations, right? So we cover event way of communicating using service-oriented communication. We cover methods. In methods, we cover file for get request response, asynchronous, synchronous, and fields you will see in coming future will be coming in the new releases.
And then once the implementation is complete, we have designed that behavior. Now we go to the implementation and deploy these services. So for deploying, the first stage is to generate the code. And if you're targeting the air XML, you can see, we can target the AUTOSAR Adaptive.
So from the previous version of architectures, you can see here the difference is that we are doing the AUTOSAR architecture. And AUTOSAR is mentioned here. And we have Adaptive AUTOSAR services.
And we have, again, defined the interfaces. We have used those new semantics that I've just recently introduced you in the previous slide. And once this Simulink behavior is all defined, I can try to just implement that. Using our code mappings and go to the AUTOSAR dictionary, I can define the service interfaces.
So if you are aware about AUTOSAR Classic approach, this is much similar to that. You also have a AUTOSAR dictionary there. Here, we have AUTOSAR Adaptive dictionary. And here, you see we have created these service interfaces mapped to those required and provided ports.
And once you select the port, you can select the behavior to the service discovery mechanisms also. And there are options to select the component for which you want to export the code. And you can configure the XML properties for which you are generating the code. And once these properties are finalized, you can select to export the code. And for the selected component, the code and XML will be generated.
So this is how we generate the code. And once the code is generated, you can see on this code perspective. So this is the code side by side. And along with that, you will see the other artifacts getting generated, like, air XML files.
So what are these air XML files? This is the code that has generated. And along with that, we have ARA Stub. And in the air XML files, we have the machine manifest, execution manifest, and the service instance manifest. So what are these manifest? They help you in deploying those services on the targets, and interact between the different other services.
And if I talk about their deployment part on the Linux targets, so we have introduced something called as Embedded Coder Support package for Linux. There, you can actually install this. It will install a Docker image onto your virtual machine within your same PC. And you can deploy using a Linux Runtime Manager app your models, which you have created as services on top of those virtual machines, and it will run on the Docker image.
So this is the Embedded Coder Support Package that I've talked about. You have a development computer and a Linux computer, which is your virtual machine. And there is a Linux target Docker container, which is having the necessary stack to run those services. And using the Linux Runtime Manager app, you can select the model and deploy it. It basically can be used for calibration measurements and testing purpose.
And from the recent version, 23b, which has been released two, three weeks back, you can deploy the whole architecture. What we have developed right now, you can deploy the whole architecture onto the virtual machine target. And we have worked with one of our partners, AWS and Elektrobit, to deploy these into virtual ECUs.
So the application that we have taken is one from the BMS and vECU. It's introducing the Sports+ mode into an EV, where it calls for a change for BMS and vECU. BMS was implemented using AUTOSAR Classic. It's running on the Synopsis Silver on top of Amazon EC2 x86 architecture.
And the vECU application was made using Adaptive AUTOSAR. It is running on top of EB Corbos middleware and running on EB Corbos Linux, which, in the end, running on the AWS Graviton instance. So it is giving you the Arm emulation. And then we have tested using some IP and Simulink test in the loop.
And with this, like I said, we have covered the modeling part. For the automation and agility, I would like to welcome Vamshi to take it further. Thanks.
Hello. Good evening, everyone. I know the energy levels are a little low. But keep up your energy level for the next, probably, 15 to 20 minutes. And I am the last speaker for today, OK?
So, thanks, Nukul, for giving very good session on service-oriented architectures, where the industry is moving. So I'll ask a question. How many of you know CI, Continuous Integration?
Now, how many of you are already using a CI environment? Or how many of your projects are already in CI environment? OK. And do we have anyone who doesn't know what is CI? OK.
So for those of you who don't know what is CI, so CI is a agile development methodology, or you can say agile development best practice, in which a developer regularly submits or merges the changes into the repository, or you can call it as a version control repository.
And then these changesets that he has submitted are merged into the repository. They'll be verified. They'll be qualified. And they'll be run. And you will get a lot of, let's say, feedback, or let's say, you will get a lot of reports out of that pipeline, which is running on your CI environment. So that is CI.
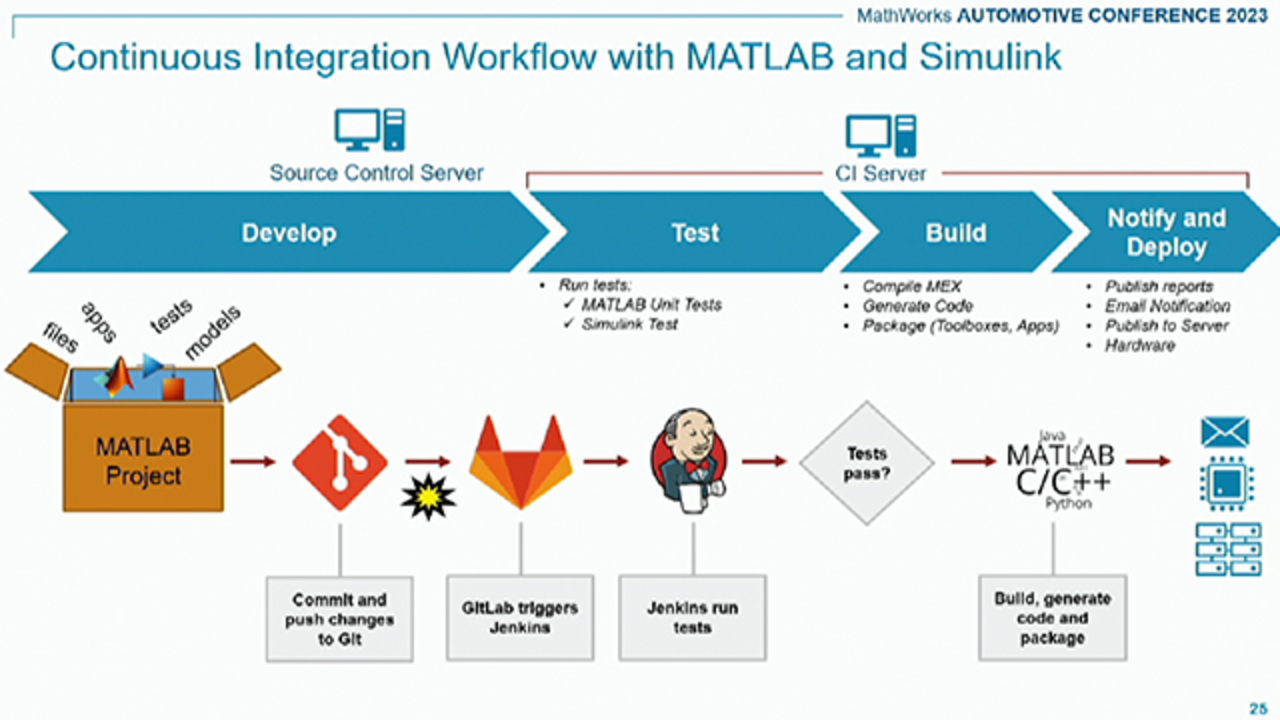
So now let's also discuss about what do we offer. What's continuous integration workflow with MATLAB and Simulink tools? OK, so if you are working on a project, there will be a lot of files, data files, model files, your test cases, reports. So you must be working with a lot of files.
All your files, you must be making some changes into your test cases or your models. So all these project files are kept in something called as MATLAB project or Simulink Project. So from there, itself, you can submit your changes into the repository.
So the version control that is here is Git. So you can push your changes into the Git repository. And then Git will trigger Jenkins. And then the Jenkins will run all your pipelines. So if your Jenkins run test case, all it passes, and then you will go on to generate the code, or let's say, compile the max, or package it into a toolbox. You can create a web app. And also, you can publish a lot of reports out of it, let's say, test case report, code generation report, multiple reports, right?
So development activity, you can develop your models, test your models at the desktop level. And then once you iterate, everything is fine, then you push your changes into your repository, Git. And then Git will trigger the Jenkins or the CI process.
So let's now discuss about a use case. So let's imagine a team is working on a cruise control system, which is already done, developed. But there is one requirement. So the requirement is a cruise control product must meet a new driver awareness requirement.
So the requirement is, if the driver awareness signal is false, then the cruise control function shall be disabled. And also, we should not be enabling that feature anywhere in the future. So the Enable shall be prevented. So these are two requirements that I got.
I mean, if you give it to any software developer, he'll think in this way. Is the driver aware? So there will be some input, driver awareness input. And then modify some logic based on it. And you have to disable the cruise control feature. So there will be some changes you need to make here. And then it will go into the production after all the test cases.
So for this, the environment or the, let's say, developing team is like this. So one team leader, who is responsible for the integration, like a manager or team lead, and then there are two control engineers who are responsible for two changes. And there is a test engineer. So different organizations have different teams, which handles different tasks.
So there is a test engineer who tests all this. And also, so the driver awareness feature must be released within weeks. So that's the requirement-- I mean, that's the timeline that-- everybody here has a timeline, right? And also, fortunately, the process had been automated. So for the speed and quality, it has been there in the, let's say, Git.
OK, now, let me go back here. So if you are working on a Simulink model or if you know MBD, model-based design, what's one big advantage of MBD? You can iterate multiple times so that you can innovate or you can find the bugs or errors early in the process.
So you make a model, you make a change, and then you, let's say, do hundreds of simulations to see if there is any problem in my code or whether my software fails at some point, and what's this file safe logic that I should add. So all this, you will think about it. So that's where simulation is very helpful. And model-based design, you all know that Simulink is a tool that really is model-based design.
So let us go through each step in this. So first, you establish the project. I said cruise control is already developed. It's there. We are just adding one more requirement, one more change into the cruise control.
So first, we need to establish project. Let's say I'm a developer. Now I need to work on the change. So first, what I should do first, I should get the whole environment into my local PC, or let's say, local laptop. And then I'll run sections of this script to perform some of the operations.
So what I'm trying to do is I'm trying to establish the project. So the project is there in, let's say, Git, GitHub. And there are set of instructions that I'm running to clone that project into my PC, let's say. OK, let me play this video.
I have these script that I have run. Sorry. I'm so sorry. So I have this script. I'm cloning the repository to get the whole Simulink project with all the model files, data files, everything into MATLAB. Once it is in MATLAB, you can open the project. And you can also see whether all the files are committed into Git or not.
And then what you will do after you establish the project is you need to create two branches. So because we have two control engineers, one will be working on prevent enable side of the change, and one will be working on disabling that cruise control thing. Create two branches. And then after creating the branches, you will make those changes.
So let me show you the model. So let's say I am making this prevent enable change. So this is my driver awareness input. And I'm in the subsystem where I need to make a change.
So I know the functionality. So using the existing Simulink model, I made few changes, which will implement this prevent enable change. OK, so now this is done. And I mean, you do the same for disable. You create a branch, and then make those changes.
Then what will happen is-- so after you make changes, you need to do a lot of test cases, where the changes that I made, whether it is giving you the required results or not. Let's say, when the driver is not aware, the cruise control is switching off or not. It should not be enabled any time in the future. So that is what we are testing.
So the one that you are looking at is a Test Manager. So it's a test case management environment, wherein you write test cases. You can create a lot of test suits, and define a lot of test cases, and give inputs, do multiple iterations of these same test cases that you have written, and then test the functionality thoroughly.
And then next, you develop the model. But how do you ensure that model is according to the standards? So there are ISO standards. There are a lot of MISRA guidelines. There are MAP guidelines to ensure.
And also, sometimes the algorithms that you have built are much more complex. So what's the complexity of the software, whether it will run as you are expecting in the target hardware. So all those things, you would like to check it. So do that static analysis to assure the structural integrity of the software or models. And then once you are happy with your test cases, once you are tested, and once you are happy with your results, then commit this work into the repository.
So let me show you that. Let me play this video again. So if you see here, on this side, the changes are there. So you see, there are some changes that you made to the model. So those will be in blue color.
Quickly, very fast. OK, so let me play this once again, this video. All right?
OK, so I made changes to the model. And I have ran the test cases. So you see my model is changed, and my test case file is also changed. So you can see here, I have ran some 10 test cases.
So these changes needs to be committed. So what I'm doing, I'm going here to Commit button, and I'm committing my changes directly from Simulink itself. So once you commit and give the proper comment, then you can also push your local repository changes into the remote repository. So that can be your Git.
The same process, as I said, can be done for another branch that you have created. But we are not showing that here. And then the next thing is you have multiple branches created. Let's say, control engineer one created one branch, and you have created your own prevent enable branch.
So now you have to merge these changes into one model, and you have to push it into your Git. So this is where you have-- before pushing into the, let's say, into your Git, you merge those changes after you commit. So let me show this video where you can merge.
So you see the branches here. So here, you can create-- I mean, I have already created multiple branches here. You can see disabled branch and prevent enable branch here. So I'm selecting prevent enable branch and trying to merge my changes. Let us see what happens.
So I merged it, but there is an error. So let's see why it is unable to execute that. Because there are multiple changes, and then it is asking us to check whether all the changes needs to be merged or not. So you can also-- I mean, from Simulink projects, there is also three way merge facility. So you see three different changes. And you understand where the change is.
Let me go here. And then you see what's the change. And if you are satisfied with all these changes-- so basically, what's happening here is-- so there is a signal builder, which is changed. OK, so you open that, and it will show you side by side what are those changes.
So here, you can clearly see request mode-- a change in the request mode. And then there is a change in driver awareness signal and all. If you're OK with all these changes, accept these changes, and then say merge.
So it'll save those changes. And then all the Save Changes are appearing here. So once you do this commit, after the merge, and then later, you can push this into the CI pipeline.
So for pushing these changes in your, let's say, local drive into your CI-- or sorry, into your Git-- so again, I'm writing some Git Bash commands, Git push command. So I'll be running these commands. And as soon as I run this command, and as soon as all the changes are submitted into your Git, your pipeline starts, because I defined the pipelines in a YAML files or YAML files. And I have created some stages in it.
So these pipelines are run. So let's say, each stage has its own activity, let's say, verify stage. It will simulate and verify. And then there is a code generation stage, or there is a static code analysis stage, or there is, let's say, verify stage, where you run all your test cases.
So I created multiple stages in this pipeline. So for every model commit, so all the whole pipeline will run. And it will ensure that you're submitting your changes. And at each stage, you don't forget to create a report, and then keep that report into a folder. So we need those reports for your ISO purposes or for process-related purposes.
Once you push your changes into Git and pipelines are run successfully, then what you do is you inspect. During this process, let's say, you have tested your code-- sorry, you tested your model. And you pushed your changes into the Git repository. But your pipelines created the code, generated the code. So one of the stage in your pipeline is generate code if all the test cases are successful.
And then what you do, you inspect the generated code. So you go into those-- I said, each stage will do some action. And then you will have a lot of reports and generated files. So you inspect those files.
So simplifying the whole thing that we have done, if you look at the whole process that we have done, there is a team, which did some interactive development. They merged those changes. They spoke with each other. And they do some interactive development and submit the changes into the source control.
And once you submit the changes into the source control, your CI/CD pulled those changes and triggered the pipeline execution. And the pipeline, a stage by stage automated process, it has done. And then it gave you some results. Or if the pipeline failed, some email notification is sent to your email ID. So all that monitoring, debugging, you will do at the pipeline execution phase, and then you will monitor the results.
So when you are at this stage, pipeline execution phase, so how do you set up this pipeline? So we just discussed about making the changes and submitting into the source control. But we didn't discuss about how do you set up this pipeline, what's the performance of that pipeline.
And a lot of you complain about, how do I-- I am running the pipeline, but the pipeline is running forever. So there is no efficiency running this pipeline. And how do I integrate these results? And when the pipeline fails, I don't know what to do. How do I debug? All those things, right?
So to answer all these questions, so we have come up with a-- we have a CI/CD automation for Simulink check support package. So this support package answers all these questions. So you can set up your pipelines quickly.
And then you can do the desktop integration with this Process Advisor app. So this Advisor app has all the sections, let's say, verify, build. So it will suggest you all the stages in the pipeline. And then you can integrate this with your third party integration. Let's say, I mean, somebody must be using Jenkins, somebody must be using AWS, Azure, Circle CI. There are many third party CI integrations exists.
So for all this, you have this CI/CD support package. It comes with your Simulink Check product. And it will enable you to do all this, like, publish the results, automated pipeline generation. You can also debug on the desktop. You can see what are those errors, changes, warnings at each stage of your pipeline. And also, you can easily integrate with your CI environment.
And if you ask me, did anyone use this whole process with Simulink? Yes. We have some user stories of these two customers.
A123 Systems, so it's a similar case study, like we have discussed here. But in the case study that we discussed, we are running-- we are submitting our changes into Git. And we are using GitLab Runner to run the whole pipeline.
But here, they have used Jenkins instead of that. So the source repository is Git. Source control repository is Git. But the CI is through Jenkins. And there is another user story, wherein HL Klemove. So they focused on the code, static analysis on the code using Polyspace.
To summarize all this, engineering, data science, IT Operation teams must collaborate to ensure the success, because some organizations have-- they let the engineers to do only the technical work. And there are other IT infrastructure team to support the whole CI pipeline and all this, right? So everybody, like, engineering, IT, everybody needs to collaborate to ensure the success.
But we as The MathWorks, MATLAB and Simulink, there are a lot of features that helps you integrate your changes or your models. You can easily integrate with your source control, as well as your CI repositories. And also, we have learned that MATLAB and Simulink model can be deployed onto the variety of platforms, Embedded Edge. So Nukul was discussing about how do you deploy it on Graviton and all those things.
So this is a high level summary. Now, me and Nukul can take some questions. So you have seen these slides. So if you are already using CI, we would like to know your inputs on it or which CI environment that you are using, or if you have any general questions, me and Nukul are here.
How many of you are aware about Jenkins, are doing CI in Jenkins? OK, so your pipelines are running fine? No issues debugging, everything is fine?
So any one of you are interested in the native cloud platforms like Azure DevOps and the AWS code commits? OK, I think we have one hand raised here. So you have a question?
You have a question?
OK. OK, I mean, any one of you are at a stage where, I want to set up my CI, or like, let's say, I want to set up my whole continuous environment, do you need support on starting this type of workflows, we are here. You can talk to us. We will help you set up this at your organization.
Any questions, we can take on CI or SOA, let us know. You can also talk to us backstage here offline. Yeah. Thank you.
Thanks.
Thanks, everybody.
Hello.
Related Products
Learn More
Featured Product
System Composer
Up Next:


Related Videos:







Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: United States.
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)