Reducing the Memory Footprint of Your Powertrain System
Using a Powertrain system example, this video demonstrates the lookup table optimization capability that enables you to compress the lookup tables in your design to reduce the RAM memory usage. You can approximate a function or an existing block with an optimal lookup table.
Designing an optimal lookup table involves various choices: fixed-point or floating-point data, size of the table, evenly spaced data or uneven spacing, and other algorithm settings such as the interpolation method. All these decisions are automated using the lookup table optimizer.
We explore the tradeoff between system behavior and efficient design as measured by the amount of memory reduced.
Published: 12 Mar 2019
Hello, everyone. I am Ram Cherukuri, product marketing manager here at MathWorks, and in this video, we will explore how to optimize the lookup tables in your designs in order to minimize the RAM usage on the target ECU, using a powertrain control example model.
First, what is lookup table optimization?
It’s a feature that allows you to optimize the data types and the various parameters of a lookup table, such as the number of breakpoints, their spacing, etc., to give you an optimal lookup table within a user-specified tolerance.
You can leverage this feature to compress lookup tables in your design to minimize the RAM footprint, and you can also use it to replace complex functions or subsystems with lookup tables for faster runtime performance.
Please refer to the documentation link and the other videos linked below to know more about how to use this feature in detail.
You have both the command line API and a UI-based app to use this feature.
We are going to use a traditional compression ignition engine model from the powertrain blockset reference example, and this model has around 31 lookup tables.
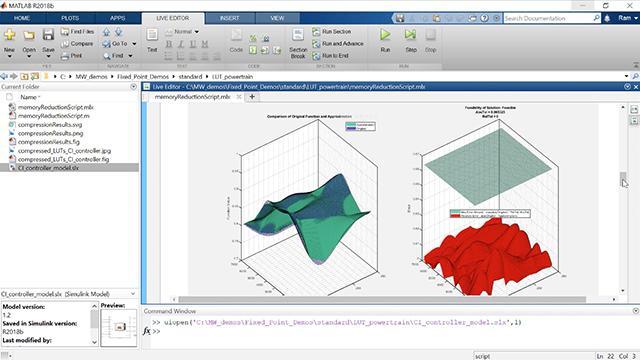
Here is the Simulink model for compression engine and we can look under the mask to explore the components of this subsystem. We will use this script to run through the steps in this example. First we are going to estimate the total memory footprint of the 31 LUTs in this model.
Now let’s pick one lookup table here for a quick test, and let’s run the optimization with a relatively large margin of tolerance on the output. We chose about 25% of absolute tolerance and a relative tolerance of 5%. Here you see how the resulting lookup table compares to the original one.
The compressed output for this particular LUT gave us a 96% reduction in memory as it uses 8-bit fixed-point data types for the table data while leaving the interface data types in double.
We experimented with various tolerance choices, and here is a graph that shows the tradeoff between memory reduction and the tolerance value.
And as you can see, even with a very strict tolerance, you can save 50% in RAM memory.
Our script performs a similar exercise, but with all the LUTs in the model and when you run the script here, you generate a similar graph that shows an 80% reduction even with the strictest tolerance values.
This clearly highlights how you can achieve efficient designs, especially when you have lot of lookup tables from calibration tasks in your model.
One last neat trick before we end the video. You can achieve lossless compression with no change in numerical behavior by choosing the second simulation in the optimization run, yet get more than 50% reduction in memory footprint as highlighted in the graph here.
Please refer to the file exchange entry linked below the video to try out this example script on your own model.

Featured Product
Fixed-Point Designer










Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: United States.
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)