Where Scalability Meets Efficiency: Using MATLAB and Cloud Computing to Run Swiss Re’s Internal Risk Model
Daniel Rubio, Swiss Re
Swiss Re is one of the world’s leading providers of reinsurance, insurance, and other forms of insurance-based risk transfer. Their internal capital adequacy model, critical for regulatory reporting and business steering, is implemented in MATLAB® and deployed as the core of a complex technology ecosystem using MATLAB Production Server™. The simulation workload is distributed to a computing cluster using MATLAB Parallel Server™. Daniel Rubio, Head of Integrated Risk IT, discusses the financial and operational benefits of the platform, Swiss Re’s cloud transformation journey, and how they are partnering with MathWorks to customize the reference architecture for Azure™ in a way that maximizes the business value.
Published: 14 Nov 2022
So let me just introduce Daniel. Daniel is head of Integrated Risk IT at Swiss Re. And he currently leads their public cloud transformation efforts. And that's what he's going to talk about to us today about where scalability meets efficiency using MATLAB in the cloud.
Thank you, Stuart. Let's see if I don't make the same mistake. Sound OK? Slides OK?
You sound OK. Your slides are not in the slide show view, though. That's the one. Perfect.
Yeah. OK, great. So thanks, Stuart. I'm actually happy that Alexander went first and talked about a few of the topics that I'm going to cover today as well. So that was a nice introduction.
As you said, I mean, this is about cloud and deployment as well and about how we use MATLAB not only to run calculations, but also to interact with the infrastructure in order that it makes our life easier.
So the introduction, I'm in about 3.3 I, mean we have an internal capital adequacy model that we used to comply with the Swiss regulators. We are a Swiss-based company, as well as for Solvency II purposes in the context of European legal entities.
I think this is the main usage, but not the only usage of the system. It's used a lot for businesses and purposes as well, like, for example, business planning. And its usage has grown significantly over the past couple of years, in particular, due to the crisis that we've been having over the past couple of years and the subsequent market volatility.
From a system perspective, I think how Alexander puts it, this is an enterprise system. So it's not someone running calculations in MATLAB. So it's a rather big and complex ecosystem that is currently running on our private cloud for three years. This works relatively well.
But also, there are a number of challenges that we have. And we are looking now for alternative platforms. We've been doing exploration work to see what's the best way of doing this public cloud transformation, which is, by the way, fully aligned with the company's cloud strategy.
And I think what we want to show today is this journey that we've been going through and where it's taking us next, how we are addressing the challenges that we have, and basically how we're working with MathWorks and other partners to take the most out of the reference architecture for Azure. So this is the goal.
But let me give you a bit of the business context first. I mentioned that the internal capital adequacy model-- I mean, this is what we used to-- again, mainly for the Swiss Solvency test. I mean, capital adequacy is probably the ratio between available capital and required capital. The available capital is an economic view. It comes from the balance sheet from group finance. The required capital is risk-based, and it comes from ourselves, from risk management, and from our platform.
And what we do is we take a lot of data, over 120 data packages. We load them into the system, and then we run a million simulations of P&L across all the risk factors. And as the required capital, we basically take the 99% shortfall, which is the average unexpected loss that occurs with a frequency of less than once in 100 years.
For Solvency II, if I'm not mistaken, we do take the 99.5% VAR. So the system has that flexibility to request whatever you want in principle out of it. So we're talking here about large-scale numerical calculations that requires a significant computing power.
From the risk perspective, I think what's quantified in the internal model, I think, is typical for a company like ours. We have insurance and reinsurance, property and casualty, life and health, significant exposure also to the financial markets and from our credit operations, which are not financial markets-related.
If we look at the relative sizes of these four blocks, I think this is public information available in our financial condition reports. So these three are on a standalone basis around 11, 12 billion US dollars. Whereas, credit without credit spread is around $3 billion, I think, as of the end of last year.
So again, this is the business, context what we use the technology for. Let's start a bit with the journey. So we implemented the system in 2017. It existed before, but basically the current version of the system.
And by the time we were in the Swiss Re data centers and old school physical infrastructure, centralized service, it took like several weeks when you wanted a new computer because somebody had to go physically into the data center and install that. So very quickly, a couple of years after that, we moved into a private cloud that was developed by Swisscom, a leading telecoms provider here in Switzerland in partnership with us as well. And they already gave us the flavor of what cloud is about, even though it's not a fully fledged public cloud like other vendors that we have out there.
So we started having virtual infrastructure, self-service capabilities, pay-per-use. But obviously, it was a limited product offering because, again, just the capabilities of the vendor and based on our requirements as well.
Here I think it's very important to say-- I mean, MATLAB, the way we use it, relies on VMs, Virtual Machines, which is infrastructure as a service. It's good to have that in Swisscom.
But as I will explain, it's not good to have that in Azure, because we don't have a team doing that for us. So we have a few challenges here that we have to overcome.
Yeah, so here we did lift and shift. It works pretty well. Here, we cannot do a lift and shift. We are looking for a significant transformation to basically make the most out of the benefits that we can realize.
So this is our enterprise system. I think on a high-level view, there are four basic components. So we have a big Oracle data warehouse with terabytes of data. We have an application layer that controls data procurement processes, as well as calculation processes.
The MATLAB part is all embedded into what we call the resistance. I will drill into that because it's the interesting part for today. And we also have the report inside, which is also based on Microsoft technology.
So when we drill down into the risk system, this is what we find. And it connects to what Alexander said, Production Server. So this is a server product that we use to deploy the different versions of the risk models. And typically, we have five versions running in parallel. Production Server exposes them to the application layer so the users can request calculations and take actions based on the different module versions.
And in addition to that, we have Parallel Server. This is the distributed computing cluster. And we do have a cluster, which is currently a persistent cluster of 18 VMs today with significant number of CPUs and memory to be able to handle our large-scale calculations and the data that they need.
And in addition to that, we have a file share here of 10 terabytes size where we have also specific folders for each of the risk versions because what we do here is the model obviously takes the data that resides on the database from all the data fix that I was explaining. And it does inject it, validates it, and saves that into MUD files.
So the input of the models are MUD files, as well as the output of the models with the realizations are MUD files. And this is basically stored here. So I think that the file share is obviously a very important component, and its performance as well because you may have 240 plus workers here at the same time, writing and reading gigabytes of data from it.
I think what works well in the current setup is we have a proprietary piece of code that we call the cluster manager. And this basically interacts with the infrastructure to turn on and off the machines, and we can then benefit from paper use. And this is working very well, and the setup is very simple, and it's all integrated for us.
What's not working so well-- and we can look into that a bit later-- is we have performance volatility, so I'm going to explain that. We have obviously, limited the scalability. We have 18 persistent DNs. We can scale as much as we want within the size. But obviously, it's very inefficient to go beyond this size. And we don't want to have an army of VMs sitting there and not being used.
And a topic, in addition, that is not working well-- I know it's a very boring topic, but it's important for us-- is the whole problematic around OS Operating System management and upgrades. So we have at the moment patching processes, which are very inefficient because they are not cloud-optimized.
And they basically assume that the VMs are running the whole time, which is not the case for us. In fact, they are not running most of the time. And there's a lot of interference between the patching process and our scaling agent that makes our life a bit difficult. So I will speak about how we plan to overcome that in the public cloud.
So let's look at the positives first. So I introduced the cluster manager. That scales the cluster up and down based on the persistent set of VMs. And this is a relatively unsophisticated but reliable piece of MATLAB code that we wrote.
And basically, what it does is it gathers information from Parallel Servers, from the job queue. It gathers information from the infrastructure through the infrastructure API and basically combines all this information to take decisions within a frequency of a minute. And it basically decides do I need more capacity?
So I need to turn on machines and install the software that they need. Or do I less capacity and I need to turn them off? So this is something that, again, it's all automated. It works very well, and it allows us to benefit from the paper use capabilities.
Now, because we are in the cloud and building happens on a real-time basis. We also have real-time information where the computing resources are running. And we can use all this information to construct basically the usage reports that we look for our IT steering purposes. So I'm going to show you how that looks and how we can benefit from that.
So let's look at this one. For example, this is daily average usage for a month. So this is the month of February, last February. And February's our most intensive month because it's SSD time. So it's relatively intense. And we see that it's totally unpredictable. But it's always less than 100% which results in savings.
If we look at monthly usage over a year, we see the same thing. We have months that are 80%. We have months, which are 35% and anywhere in between. So again, it's a bit unpredictable, but good when it doesn't reach 100% because we can save money.
And if we look at annual usage, we see that it's, again, the same thing. Anything that is here not close to 100% is good for us. And we see that we can reduce usage year on year by improving the code, by improving the infrastructure. And here in this case, we've done it despite the fact that the usage of the calculation, let's say, the number of calculations that we run more than doubled in the same period. So I think it's a great piece of work by the team.
And if I have to say it, a dollar amount that we have in savings here is probably, over the past three years, a couple of $100,000 US dollars through this cluster manager application. And it is obviously not insignificant. So this is what works well.
Let's look into the performance challenges that we have. And this is due to over-commitment. I mean, the cloud that we have now is basically sharing infrastructure. And for those of you that are not familiar with it, basically you have physical hosts that have a certain size. And then you have the virtualization layer, the hypervisor, which is creating virtual machines on the top of that physical host.
And sometimes, the combined size of these machines is basically higher than the original physical host, which basically means that these computing resources here are basically sharing the computing power that the physical host provides. And that leads to performance regression and performance volatility. And this frustrates our users because they can't really predict when a certain calculation is going to end.
How do we notice that? Basically, like this. These blue bars are 40 workers doing exactly the same computational job. So they always start at the same time. And we see that a number of them, which are basically a group to one of the virtual machines, finishes here. So we've normalized that to the faster worker.
A second group is relatively slower. And the third group of them is much lower, which basically means that this is the slower worker here. And all the workers, until this one, they basically have to wait until this one finishes, which means that they're wasting time. And when we do that repeatedly, obviously, throughout the entire process, we lose a lot of time.
So what can we do about that? First of all, I mean, obviously old school, line by line code improvements. So that works and we've done it in certain phases. We have last year an infrastructure upgrade in the private cloud. So by doing that, we realize that it handles our commitment better, and you see the effect less.
But I think here the game changes are obviously the job architectures to make these parts and these spaces more independent and more modular. I'm going to show you that and basically change the platform.
Let's look at the software architecture. And this is a great piece of work that has been done by the risk modeling colleagues. And what we did is we started with a fixed set of workers, 40 workers doing 40 equal massive jobs.
And we've broken down into much smaller jobs, basically in the thousands, which are asynchronous or independent. And we can basically run that in any arbitrary pool of workers. So we call this the elephant and the mice architecture.
And the benefits, they are very obvious. Obviously, from a scalability perspective, we can decide, again, before we were fixed to 40 workers-- and then we can decide, do we want to use more workers for the same calculation so it's faster? Or do we want to use less if I'm running a job, for example, overnight and I'm not going to wake up to look at the results?
And this is giving us a lot of more flexibility. Obviously, modularity is very important as well. But resilience is also very important.
For example, before with the old setup with the elephants, any job that failed basically made the entire process failed. Then we have to restart it from scratch because the jobs now are independent. If they fail for a temporary glitch-- for example, like out of memory or like a connection problem-- it would be retried because it's independent. And eventually, it will recover from that and complete the whole end-to-end process, which is much better than before.
And from a performance perspective, what we do is we don't have to wait for-- there's no worker anymore because the jobs are independent. So we see here that this low worker is taking a lot of time to complete the previous phase. But the other workers in the pool, they basically moved on. And they will compensate the time that the other one is losing. And basically, there's going to be a minor delay at the end because we still have a slower worker, but it's not as big as the one before.
So we've done this. This is already in production, even in the private cloud that we have it today. And it's bringing significant benefits.
So this is so much for the current state. Let's look at the public cloud. And the public cloud, I mean, we entry-- we know the reference architecture that MathWorks provides for Parallel Server. This is based on VM skill sets, and this is working very well.
But before that, we wanted to test the capabilities that we have there and the optionality that we have in Azure, which is much bigger than what we have before. So we created a manually-installed cluster. And we started doing tests there.
But before moving into the tests, let me talk about the ambitions that we have here that we're trying to fulfill with the public cloud setup, which is performance. Obviously, we want to be faster in the process in time. Scalability, we don't want to be limited to a given size in the pool. We want to be more scalable up to a certain quota-- obviously that Microsoft is going to give us some of the economics that we can afford.
Availability, this is the patching question that I mentioned. We want to gain some time out of the process. And obviously, we want to have additional options to optimize the cost that we may not have today. So this is what we're looking for. And I leave this down here so I can revise that as we go.
First of all, we started doing our tests. And basically, because we have a lot of options that we didn't have before, so we started looking at what compute in virtual machine families that we have in Azure, storage tiers, network configuration, operating system, and software. And we try a lot of combinations of these to see what basically is kind of the sweet spot that we can find.
And I'm going to show you an example here. The example was about computing. And this was very surprising because when we compare what we have today with a number of VM families or VMs that we have in Azure today, we found something unexpected, which is some of the high-performance computing families are basically a bit slower than what we have.
So we realized that the computing alone is not so important as the combination of computing memory and IO. And when we started using memory-optimized VMs, then the situation got better into obviously a satisfactory way.
This is with the elephant's configuration. Sorry, if we look at the mice architecture, we can get a few more performance points out of the same configuration. And this is something obviously that it's a very good and pleasant surprise and performance levels that we are happy with. So I'm happy to take here the performance on this end.
And moving to the next one. Then we moved from the self-installed cluster to the reference architecture. And then we go into the Azure marketplace, we can deploy within a click of a button.
We select we want parallel the server. We start entering the configuration, that we want, the parameters that we want. And basically, what it's going to happen is there is a deployment process in the background. So it takes a computing image that has been defined by MATLAB MathWorks with the corresponding MATLAB version.
It deploys the infrastructure components. It brings them together, and it runs some post-deployment scripts to install and configure Parallel Server, not just in the head server, but in the VM scale set as well.
And when we do that, we realize that it fails. I mean this, approach doesn't work for us because we have internal security restrictions in the company that prevents us from using the public cloud in a very broad way. And the challenge here is, for example, public IP addresses, which are not allowed in our setup.
So we work with MathWorks to work around that. And basically, what we did is we customized the deployment template to replace the default virtual network with our own virtual network which has private endpoints. And we removed the public ones both in the deployment process and in the configuration scripts. And we basically made the whole thing work.
And once we have it deployed, basically, we start looking at what can we do with it. And the point is the scaling. So we will look at the scaling. And obviously, the scaling options in Azure, they are broad as well.
You can do manual scaling and it works very well for testing, but obviously not for productive environments. So that doesn't help us. We looked at other options. Obviously, standard autoscale is rule-based. We cannot optimize enough.
Predictive after-scale machine learning-based, but more for cyclic patterns, usage patterns. That's also not our case. And schedule doesn't really help us either. So we are back to programmatic scaling.
And basically, we can amend our cluster manager to work in the cluster in the new setup. And the approach is twofold. The differences are, first of all, we don't configure MJs ourself. This is done by the deployment process in this case.
And very big difference here-- we do not create turn on and off machines. We basically create them on the spot. And we destroy them after the calculation is being performed.
And this is for us, it's working great. And it basically unlocks unprecedented scaling in a very efficient way that allows us to deploy a cluster of the size of my production cluster today in a matter of minutes, within a click of a button, instead of a matter of days before. And this is great for us.
So let me skip this part because I'm running out of time. So this is giving me the scalability on the availability side. Let me spend the last couple of minutes there. What we did basically is we created also a custom image for the computing cluster, for the BM scale sets.
We worked with MathWorks already to do that from scratch because we wanted to have more flexibility, not only with the operating system, but with the MATLAB versions. But also, as MathWorks pointed out in the presentation today and looking at the interoperability between different programming languages, we wanted to have more flexibility as well. So we then added Python to our custom image to make sure that we have that flexibility as well, and explore how can we use it in the future. So that was also important for us.
But basically, having the custom computing image by itself doesn't give us the availability. It's about how we use this image that gives us the additional availability. And what we're doing here is we basically generate a custom image from an up-to-date operating system that is fully patched. We update the scale set with this custom image, and then the cluster manager starts running processes creating and destroying VMs based on this patched image as well.
And after a certain time, the day after, a week after, we can define that. We recreate another image and so forth. And we can continue doing.
What we've done with this approach is basically we've moved the patch in from this layer down here, where it impacts the user and reduces the application availability, to this layer up here, where it happens now offline. And that basically brings us the additional availability requirements that we want to have. We probably gain around one to two days per month of additional computational time with this approach.
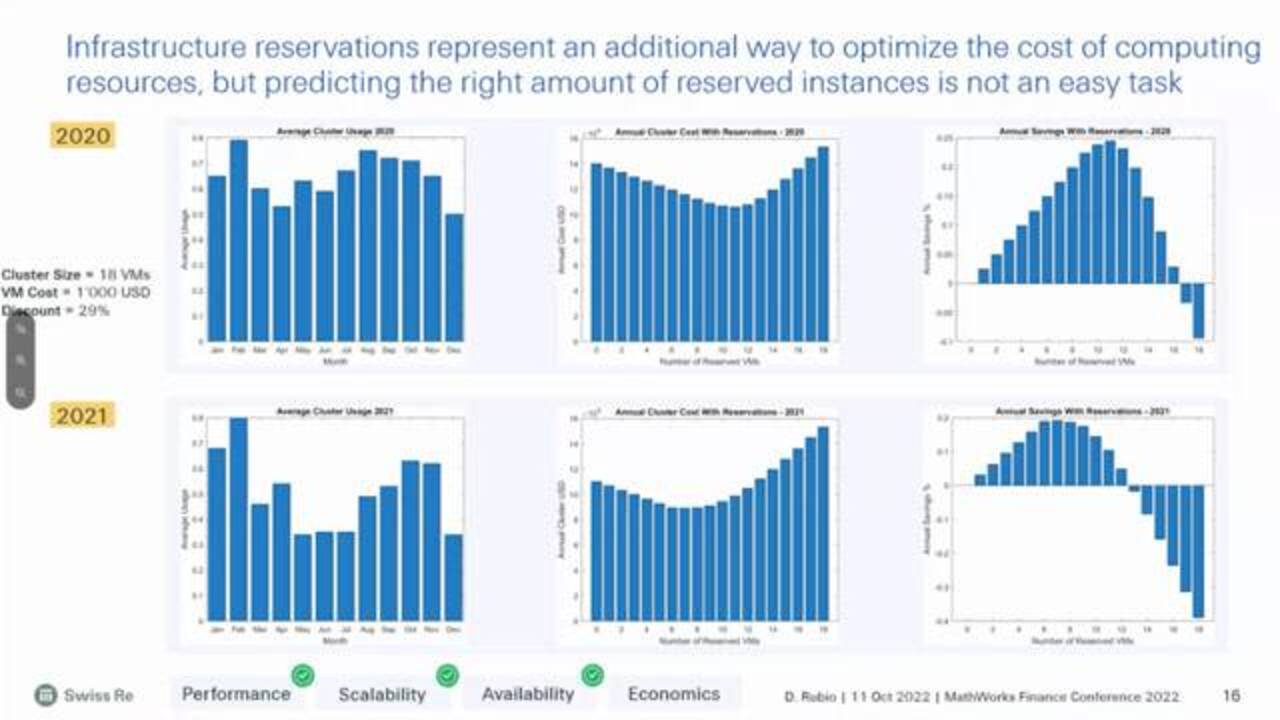
And the fixed availability part-- and the last thing I'll spend the last minute on the economics. What we do is we can do a national VM reservations as well. So if you do a reservation for the VM family that we want to use, it gives us a 29% discount.
And basically, what we do is we can backtest this approach to the usage that we had in the previous years to see how it basically optimizes our overall cost. And we see that, based on this usage, the total cost of the computing cluster, when I add reservations, it basically has a minimum around 11, 10 to 12 VMs for a cluster of size 18, which is what I have today, and for a usage of relative 60%, which is what I had this year. And that basically gives us an additional discount of close to 25%.
But again, you have to be very careful because if you add too many reservations you start losing this effect. And eventually, you try and you start losing money. And for the year later, where we have less consumption, obviously, the effect is less. We can realize as much saving, but also it still adds value.
So we have now this framework. And based on the size of the cluster and expected usage, we can come up with a number that is going to give us, again, additional flexibility to optimize the economics. And we're happy with that as well.
So in this, I'm basically three minutes after, and I come to an end. And I basically wanted to acknowledge a few people that have contributed to this work, either physically or intellectually. Thank you.
Featured Product
MATLAB
Up Next:


Related Videos:








Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: United States.
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)