Supervised Learning Workflow and Algorithms
What Is Supervised Learning?
The aim of supervised, machine learning is to build a model that makes predictions based on evidence in the presence of uncertainty. As adaptive algorithms identify patterns in data, a computer "learns" from the observations. When exposed to more observations, the computer improves its predictive performance.
Specifically, a supervised learning algorithm takes a known set of input data and known responses to the data (output), and trains a model to generate reasonable predictions for the response to new data.
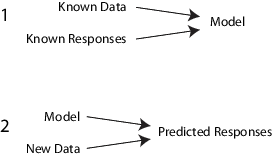
For example, suppose you want to predict whether someone will have a heart attack within a year. You have a set of data on previous patients, including age, weight, height, blood pressure, etc. You know whether the previous patients had heart attacks within a year of their measurements. So, the problem is combining all the existing data into a model that can predict whether a new person will have a heart attack within a year.
You can think of the entire set of input data as a heterogeneous matrix. Rows of the matrix are called observations, examples, or instances, and each contain a set of measurements for a subject (patients in the example). Columns of the matrix are called predictors, attributes, or features, and each are variables representing a measurement taken on every subject (age, weight, height, etc. in the example). You can think of the response data as a column vector where each row contains the output of the corresponding observation in the input data (whether the patient had a heart attack). To fit or train a supervised learning model, choose an appropriate algorithm, and then pass the input and response data to it.
Supervised learning splits into two broad categories: classification and regression.
In classification, the goal is to assign a class (or label) from a finite set of classes to an observation. That is, responses are categorical variables. Applications include spam filters, advertisement recommendation systems, and image and speech recognition. Predicting whether a patient will have a heart attack within a year is a classification problem, and the possible classes are
trueandfalse. Classification algorithms usually apply to nominal response values. However, some algorithms can accommodate ordinal classes (seefitcecoc).In regression, the goal is to predict a continuous measurement for an observation. That is, the responses variables are real numbers. Applications include forecasting stock prices, energy consumption, or disease incidence.
Statistics and Machine Learning Toolbox™ supervised learning functionalities comprise a stream-lined, object framework. You can efficiently train a variety of algorithms, combine models into an ensemble, assess model performances, cross-validate, and predict responses for new data.
Steps in Supervised Learning
While there are many Statistics and Machine Learning Toolbox algorithms for supervised learning, most use the same basic workflow for obtaining a predictor model. (Detailed instruction on the steps for ensemble learning is in Framework for Ensemble Learning.) The steps for supervised learning are:
Prepare Data
All supervised learning methods start with an input data matrix, usually called X here. Each row of X represents one observation. Each column of X represents one variable, or predictor. Represent missing entries with NaN values in X. Statistics and Machine Learning Toolbox supervised learning algorithms can handle NaN values, either by ignoring them or by ignoring any row with a NaN value.
You can use various data types for response data Y. Each element in Y represents the response to the corresponding row of X. Observations with missing Y data are ignored.
For regression,
Ymust be a numeric vector with the same number of elements as the number of rows ofX.For classification,
Ycan be any of these data types. This table also contains the method of including missing entries.Data Type Missing Entry Numeric vector NaNCategorical vector <undefined>Character array Row of spaces String array <missing>or""Cell array of character vectors ''Logical vector (Cannot represent)
Choose an Algorithm
There are tradeoffs between several characteristics of algorithms, such as:
Speed of training
Memory usage
Predictive accuracy on new data
Transparency or interpretability, meaning how easily you can understand the reasons an algorithm makes its predictions
Details of the algorithms appear in Characteristics of Classification Algorithms. More detail about ensemble algorithms is in Choose an Applicable Ensemble Aggregation Method.
Fit a Model
The fitting function you use depends on the algorithm you choose.
| Algorithm | Fitting Function for Classification | Fitting Function for Regression |
|---|---|---|
| Decision trees | fitctree | fitrtree |
| Discriminant analysis | fitcdiscr | Not applicable |
| Ensembles (for example, Random Forests [1]) | fitcensemble, TreeBagger | fitrensemble, TreeBagger |
| Gaussian kernel model | fitckernel (SVM and logistic regression learners) | fitrkernel (SVM and least-squares regression learners) |
| Gaussian process regression (GPR) | Not applicable | fitrgp |
| Generalized additive model (GAM) | fitcgam | fitrgam |
| k-nearest neighbors | fitcknn | Not applicable |
| Linear model | fitclinear (SVM and logistic
regression) | fitrlinear (SVM and least-squares
regression) |
| Multiclass, error-correcting output codes (ECOC) model for SVM or other classifiers | fitcecoc | Not applicable |
| Naive Bayes model | fitcnb | Not applicable |
| Neural network model | fitcnet | fitrnet |
| Support vector machines (SVM) | fitcsvm | fitrsvm |
For a comparison of these algorithms, see Characteristics of Classification Algorithms.
Choose a Validation Method
The three main methods to examine the accuracy of the resulting fitted model are:
Examine the resubstitution error. For examples, see:
Examine the cross-validation error. For examples, see:
Examine the out-of-bag error for bagged decision trees. For examples, see:
Examine Fit and Update Until Satisfied
After validating the model, you might want to change it for better accuracy, better speed, or to use less memory.
Change fitting parameters to try to get a more accurate model. For examples, see:
Change fitting parameters to try to get a smaller model. This sometimes gives a model with more accuracy. For examples, see:
Try a different algorithm. For applicable choices, see:
When satisfied with a model of some types, you can trim it using the appropriate
compact function (compact for classification trees, compact for regression trees, compact for discriminant analysis, compact for
naive Bayes, compact for
SVM, compact for ECOC models, compact for classification ensembles, and compact for regression ensembles). compact
removes training data and other properties not required for prediction, e.g., pruning
information for decision trees, from the model to reduce memory consumption. Because
kNN classification models require all of the training data to predict
labels, you cannot reduce the size of a ClassificationKNN model.
Use Fitted Model for Predictions
To predict classification or regression response for most fitted models, use the predict method:
Ypredicted = predict(obj,Xnew)
objis the fitted model or fitted compact model.Xnewis the new input data.Ypredictedis the predicted response, either classification or regression.
Characteristics of Classification Algorithms
This table shows typical characteristics of the various supervised learning algorithms. The characteristics in any particular case can vary from the listed ones. Use the table as a guide for your initial choice of algorithms. Decide on the tradeoff you want in speed, memory usage, flexibility, and interpretability.
Tip
Try a decision tree or discriminant first, because these classifiers are fast and easy to interpret. If the models are not accurate enough predicting the response, try other classifiers with higher flexibility.
To control flexibility, see the details for each classifier type. To avoid overfitting, look for a model of lower flexibility that provides sufficient accuracy.
| Classifier | Multiclass Support | Categorical Predictor Support | Prediction Speed | Memory Usage | Interpretability |
|---|---|---|---|---|---|
Decision Trees — fitctree | Yes | Yes | Fast | Small | Easy |
Discriminant analysis
— fitcdiscr | Yes | No | Fast | Small for linear, large for quadratic | Easy |
SVM — fitcsvm | No. Combine multiple binary SVM classifiers using fitcecoc. | Yes | Medium for linear. Slow for others. | Medium for linear. All others: medium for multiclass, large for binary. | Easy for linear SVM. Hard for all other kernel types. |
Naive Bayes —
fitcnb | Yes | Yes | Medium for simple distributions. Slow for kernel distributions or high-dimensional data | Small for simple distributions. Medium for kernel distributions or high-dimensional data | Easy |
Nearest neighbor —
fitcknn | Yes | Yes | Slow for cubic. Medium for others. | Medium | Hard |
Ensembles —
fitcensemble and fitrensemble | Yes | Yes | Fast to medium depending on choice of algorithm | Low to high depending on choice of algorithm. | Hard |
The results in this table are based on an analysis of many data sets. The data sets in the study have up to 7000 observations, 80 predictors, and 50 classes. This list defines the terms in the table.
Speed:
Fast — 0.01 second
Medium — 1 second
Slow — 100 seconds
Memory
Small — 1MB
Medium — 4MB
Large — 100MB
Note
The table provides a general guide. Your results depend on your data and the speed of your machine.
Categorical Predictor Support
This table describes the data-type support of predictors for each classifier.
| Classifier | All predictors numeric | All predictors categorical | Some categorical, some numeric |
|---|---|---|---|
| Decision Trees | Yes | Yes | Yes |
| Discriminant Analysis | Yes | No | No |
| SVM | Yes | Yes | Yes |
| Naive Bayes | Yes | Yes | Yes |
| Nearest Neighbor | Euclidean distance only | Hamming distance only | No |
| Ensembles | Yes | Yes, except subspace ensembles of discriminant analysis classifiers | Yes, except subspace ensembles |
Misclassification Cost Matrix, Prior Probabilities, and Observation Weights
When you train a classification model, you can specify the misclassification cost
matrix, prior probabilities, and observation weights by using the Cost,
Prior, and Weights name-value arguments,
respectively. Classification learning algorithms use the specified values for cost-sensitive
learning and evaluation.
Specify Cost, Prior, and Weights Name-Value Arguments
Suppose that you specify Cost as C,
Prior as p, and Weights as
w. The values C, p, and
w have the forms
C is a K-by-K numeric matrix, where K is the number of classes. cij = C(i,j) is the cost of classifying an observation into class j when its true class is i.
wj is the observation weight for observation j, and n is the number of observations.
p is a
1-by-K numeric vector, where pk is the prior probability of the class k. If you specifyPrioras"empirical", then the software sets pk to the sum of observation weights for the observations in class k:
Cost, Prior, and W Properties of Classification Model
The software stores the user-specified cost matrix (C) in the
Cost property as is, and stores the prior probabilities and
observation weights in the Prior and W properties,
respectively, after normalization.
A classification model trained by the fitcdiscr, fitcgam,
fitcknn, fitcnb, or fitcnet
function uses the Cost property for prediction, but the functions do
not use Cost for training. Therefore, the Cost
property of the model is not read-only; you can change the property value by using dot
notation after creating the trained model. For models that use Cost for
training, the property is read-only.
The software normalizes the prior probabilities to sum to 1 and normalizes observation weights to sum up to the value of the prior probability in the respective class.
Cost-Sensitive Learning
These classification models support cost-sensitive learning:
Classification decision tree, trained by
fitctreeClassification ensemble, trained by
fitcensembleorTreeBaggerGaussian kernel classification with SVM and logistic regression learners, trained by
fitckernelMulticlass, error-correcting output codes (ECOC) model, trained by
fitcecocLinear classification for SVM and logistic regression, trained by
fitclinearSVM classification, trained by
fitcsvm
The fitting functions use the misclassification cost matrix specified by the
Cost name-value argument for model training. Approaches to
cost-sensitive learning vary from one classifier to another.
fitcecocconverts the specified cost matrix and prior probability values for multiclass classification into the values for binary classification for each binary learner. For more information, see Prior Probabilities and Misclassification Cost.fitctreeapplies average cost correction for growing a tree.fitcensemble,TreeBagger,fitckernel,fitclinear, andfitcsvmadjust prior probabilities and observation weights for the specified cost matrix.fitcensembleandTreeBaggergenerate in-bag samples by oversampling classes with large misclassification costs and undersampling classes with small misclassification costs. Consequently, out-of-bag samples have fewer observations from classes with large misclassification costs and more observations from classes with small misclassification costs. If you train a classification ensemble using a small data set and a highly skewed cost matrix, then the number of out-of-bag observations per class might be very low. Therefore, the estimated out-of-bag error can have a large variance and might be difficult to interpret. The same phenomenon can occur for classes with large prior probabilities.
Adjust Prior Probabilities and Observation Weights for Misclassification Cost
Matrix. For model training, the fitcensemble, TreeBagger, fitckernel,
fitclinear, and fitcsvm functions update the class prior probabilities
p to p* and the
observation weights w to
w* to incorporate the penalties
described in the cost matrix C.
For a binary classification model, the software completes these steps:
Update p to incorporate the cost matrix C.
Normalize so that the updated prior probabilities sum to 1.
Remove observations from the training data corresponding to classes with zero prior probability.
Normalize the observation weights wj to sum up to the updated prior probability of the class to which the observation belongs. That is, the normalized weight for observation j in class k is
Remove observations that have zero weight.
If you have three or more classes for an ensemble model, trained by fitcensemble or TreeBagger, the software also adjusts prior
probabilities for the misclassification cost matrix. This conversion is more complex.
First, the software attempts to solve a matrix equation described in Zhou and Liu [2]. If the software fails to find a
solution, it applies the “average cost” adjustment described in Breiman et
al. [3]. For more information, see
Zadrozny et al. [4].
Cost-Sensitive Evaluation
You can account for the cost imbalance in classification models and data sets by conducting a cost-sensitive analysis:
Perform a cost-sensitive test by using the
compareHoldoutortestcholdoutfunction. Both functions statistically compare the predictive performance of two classification models by including a cost matrix in the analysis. For details, see Cost-Sensitive Testing.Compare observed misclassification costs, returned by the object functions
loss,resubLoss, andkfoldLossof classification models. Specify theLossFunname-value argument as"classifcost". The functions return a weighted average misclassification cost of the input data, training data, and data for cross-validation, respectively. For details, see the object function reference page of any classification model object. For example, see Classification Loss.
For an example of cost-sensitive evaluation, see Conduct Cost-Sensitive Comparison of Two Classification Models.
References
[1] Breiman, L. "Random Forests." Machine Learning 45, 2001, pp. 5–32.
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)