Neuron Model
Simple Neuron
The fundamental building block for neural networks is the single-input neuron, such as this example.

There are three distinct functional operations that take place in this example neuron. First, the scalar input p is multiplied by the scalar weight w to form the product wp, again a scalar. Second, the weighted input wp is added to the scalar bias b to form the net input n. (In this case, you can view the bias as shifting the function f to the left by an amount b. The bias is much like a weight, except that it has a constant input of 1.) Finally, the net input is passed through the transfer function f, which produces the scalar output a. The names given to these three processes are: the weight function, the net input function and the transfer function.
For many types of neural networks, the weight function is a
product of a weight times the input, but other weight functions (e.g., the distance between
the weight and the input, |w − p|) are sometimes used.
(For a list of weight functions, type help nnweight.) The most common net
input function is the summation of the weighted inputs with the bias, but other operations,
such as multiplication, can be used. (For a list of net input functions, type help
nnnetinput.) Introduction to Radial Basis Neural Networks discusses how distance can be used as
the weight function and multiplication can be used as the net input function. There are also
many types of transfer functions. Examples of various transfer functions are in Transfer Functions. (For a list of transfer
functions, type help nntransfer.)
Note that w and b are both adjustable scalar parameters of the neuron. The central idea of neural networks is that such parameters can be adjusted so that the network exhibits some desired or interesting behavior. Thus, you can train the network to do a particular job by adjusting the weight or bias parameters.
All the neurons in the Deep Learning Toolbox™ software have provision for a bias, and a bias is used in many of the examples and is assumed in most of this toolbox. However, you can omit a bias in a neuron if you want.
Transfer Functions
Many transfer functions are included in the Deep Learning Toolbox software.
Two of the most commonly used functions are shown below.
The following figure illustrates the linear transfer function.

Neurons of this type are used in the final layer of multilayer networks that are used as function approximators. This is shown in Multilayer Shallow Neural Networks and Backpropagation Training.
The sigmoid transfer function shown below takes the input, which can have any value between plus and minus infinity, and squashes the output into the range 0 to 1.
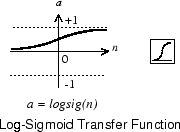
This transfer function is commonly used in the hidden layers of multilayer networks, in part because it is differentiable.
The symbol in the square to the right of each transfer function graph shown above represents the associated transfer function. These icons replace the general f in the network diagram blocks to show the particular transfer function being used.
For a complete list of transfer functions, type help nntransfer. You
can also specify your own transfer functions.
Neuron with Vector Input
The simple neuron can be extended to handle inputs that are vectors. A neuron with a single R-element input vector is shown below. Here the individual input elements
are multiplied by weights
and the weighted values are fed to the summing junction. Their sum is simply Wp, the dot product of the (single row) matrix W and the vector p. (There are other weight functions, in addition to the dot product, such as the distance between the row of the weight matrix and the input vector, as in Introduction to Radial Basis Neural Networks.)
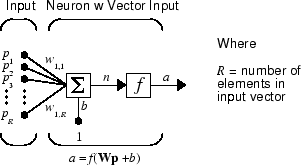
The neuron has a bias b, which is summed with the weighted inputs to form the net input n. (In addition to the summation, other net input functions can be used, such as the multiplication that is used in Introduction to Radial Basis Neural Networks.) The net input n is the argument of the transfer function f.
This expression can, of course, be written in MATLAB® code as
n = W*p + b
However, you will seldom be writing code at this level, for such code is already built into functions to define and simulate entire networks.
Abbreviated Notation
The figure of a single neuron shown above contains a lot of detail. When you consider networks with many neurons, and perhaps layers of many neurons, there is so much detail that the main thoughts tend to be lost. Thus, the authors have devised an abbreviated notation for an individual neuron. This notation, which is used later in circuits of multiple neurons, is shown here.
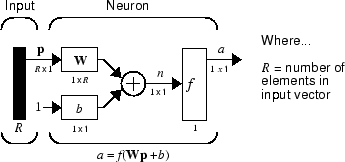
Here the input vector p is represented by the solid dark vertical bar at the left. The dimensions of p are shown below the symbol p in the figure as R × 1. (Note that a capital letter, such as R in the previous sentence, is used when referring to the size of a vector.) Thus, p is a vector of R input elements. These inputs postmultiply the single-row, R-column matrix W. As before, a constant 1 enters the neuron as an input and is multiplied by a scalar bias b. The net input to the transfer function f is n, the sum of the bias b and the product Wp. This sum is passed to the transfer function f to get the neuron's output a, which in this case is a scalar. Note that if there were more than one neuron, the network output would be a vector.
A layer of a network is defined in the previous figure. A layer includes the weights, the multiplication and summing operations (here realized as a vector product Wp), the bias b, and the transfer function f. The array of inputs, vector p, is not included in or called a layer.
As with the Simple Neuron, there are three operations that take place in the layer: the weight function (matrix multiplication, or dot product, in this case), the net input function (summation, in this case), and the transfer function.
Each time this abbreviated network notation is used, the sizes of the matrices are shown just below their matrix variable names. This notation will allow you to understand the architectures and follow the matrix mathematics associated with them.
As discussed in Transfer Functions, when a specific transfer function is to be used in a figure, the symbol for that transfer function replaces the f shown above. Here are some examples.
