Train Network Using Custom Training Loop
This example shows how to train a network that classifies handwritten digits with a custom learning rate schedule.
You can train most types of neural networks using the trainnet and trainingOptions functions. If the trainingOptions function does not provide the options you need (for example, a custom solver), then you can define your own custom training loop using dlarray and dlnetwork objects for automatic differentiation. For an example showing how to retrain a pretrained deep learning network using the trainnet function, see Retrain Neural Network to Classify New Images.
Training a deep neural network is an optimization task. By considering a neural network as a function , where is the network input, and is the set of learnable parameters, you can optimize so that it minimizes some loss value based on the training data. For example, optimize the learnable parameters such that for a given inputs with a corresponding targets , they minimize the error between the predictions and .
The loss function used depends on the type of task. For example:
For classification tasks, you can minimize the cross entropy error between the predictions and targets.
For regression tasks, you can minimize the mean squared error between the predictions and targets.
You can optimize the objective using gradient descent: minimize the loss by iteratively updating the learnable parameters by taking steps towards the minimum using the gradients of the loss with respect to the learnable parameters. Gradient descent algorithms typically update the learnable parameters by using a variant of an update step of the form , where is the iteration number, is the learning rate, and denotes the gradients (the derivatives of the loss with respect to the learnable parameters).
This example trains a network to classify handwritten digits with the stochastic gradient descent algorithm (without momentum).
Load Training Data
Load the digits data as an image datastore using the imageDatastore function and specify the folder containing the image data.
unzip("DigitsData.zip") imds = imageDatastore("DigitsData", ... IncludeSubfolders=true, ... LabelSource="foldernames");
Partition the data into training and test sets. Set aside 10% of the data for testing using the splitEachLabel function.
[imdsTrain,imdsTest] = splitEachLabel(imds,0.9,"randomize");The network used in this example requires input images of size 28-by-28-by-1. To automatically resize the training images, use an augmented image datastore. Specify additional augmentation operations to perform on the training images: randomly translate the images up to 5 pixels in the horizontal and vertical axes. Data augmentation helps prevent the network from overfitting and memorizing the exact details of the training images.
inputSize = [28 28 1]; pixelRange = [-5 5]; imageAugmenter = imageDataAugmenter( ... RandXTranslation=pixelRange, ... RandYTranslation=pixelRange); augimdsTrain = augmentedImageDatastore(inputSize(1:2),imdsTrain,DataAugmentation=imageAugmenter);
To automatically resize the test images without performing further data augmentation, use an augmented image datastore without specifying any additional preprocessing operations.
augimdsTest = augmentedImageDatastore(inputSize(1:2),imdsTest);
Determine the number of classes in the training data.
classes = categories(imdsTrain.Labels); numClasses = numel(classes);
Define Network
Define the network for image classification.
For image input, specify an image input layer with input size matching the training data.
Do not normalize the image input, set the
Normalizationoption of the input layer to"none".Specify three convolution-batchnorm-ReLU blocks.
Pad the input to the convolution layers such that the output has the same size by setting the
Paddingoption to"same".For the first convolution layer specify 20 filters of size 5. For the remaining convolution layers specify 20 filters of size 3.
For classification, specify a fully connected layer with size matching the number of classes
To map the output to probabilities, include a softmax layer.
When training a network using a custom training loop, do not include an output layer.
layers = [
imageInputLayer(inputSize,Normalization="none")
convolution2dLayer(5,20,Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer(3,20,Padding="same")
batchNormalizationLayer
reluLayer
convolution2dLayer(3,20,Padding="same")
batchNormalizationLayer
reluLayer
fullyConnectedLayer(numClasses)
softmaxLayer];Create a dlnetwork object from the layer array.
net = dlnetwork(layers)
net =
dlnetwork with properties:
Layers: [12×1 nnet.cnn.layer.Layer]
Connections: [11×2 table]
Learnables: [14×3 table]
State: [6×3 table]
InputNames: {'imageinput'}
OutputNames: {'softmax'}
Initialized: 1
View summary with summary.
Define Model Loss Function
Training a deep neural network is an optimization task. By considering a neural network as a function , where is the network input, and is the set of learnable parameters, you can optimize so that it minimizes some loss value based on the training data. For example, optimize the learnable parameters such that for a given inputs with a corresponding targets , they minimize the error between the predictions and .
Define the modelLoss function. The modelLoss function takes a dlnetwork object net, a mini-batch of input data X with corresponding targets T and returns the loss, the gradients of the loss with respect to the learnable parameters in net, and the network state. To compute the gradients automatically, use the dlgradient function.
function [loss,gradients,state] = modelLoss(net,X,T) % Forward data through network. [Y,state] = forward(net,X); % Calculate cross-entropy loss. loss = crossentropy(Y,T); % Calculate gradients of loss with respect to learnable parameters. gradients = dlgradient(loss,net.Learnables); end
Define SGD Function
Create the function sgdStep that takes the parameters and the gradients of the loss with respect to the parameters, and returns the updated parameters using the stochastic gradient descent algorithm, expressed as , where is the iteration number, is the learning rate, and denotes the gradients (the derivatives of the loss with respect to the learnable parameters).
function parameters = sgdStep(parameters,gradients,learnRate) parameters = parameters - learnRate .* gradients; end
Defining a custom update function is not a necessary step for custom training loops. Alternatively, you can use built in update functions like sgdmupdate, adamupdate, and rmspropupdate.
Specify Training Options
Train for fifteen epochs with a mini-batch size of 128 and a learning rate of 0.01.
numEpochs = 15; miniBatchSize = 128; learnRate = 0.01;
Train Model
Create a minibatchqueue object that processes and manages mini-batches of images during training. For each mini-batch:
Use the custom mini-batch preprocessing function
preprocessMiniBatch(defined at the end of this example) to convert the targets to one-hot encoded vectors.Format the image data with the dimension labels
"SSCB"(spatial, spatial, channel, batch). By default, theminibatchqueueobject converts the data todlarrayobjects with underlying typesingle. Do not format the targets.Discard partial mini-batches.
Train on a GPU if one is available. By default, the
minibatchqueueobject converts each output to agpuArrayif a GPU is available. Using a GPU requires Parallel Computing Toolbox™ and a supported GPU device. For information on supported devices, see GPU Computing Requirements (Parallel Computing Toolbox).
mbq = minibatchqueue(augimdsTrain,... MiniBatchSize=miniBatchSize,... MiniBatchFcn=@preprocessMiniBatch,... MiniBatchFormat=["SSCB" ""], ... PartialMiniBatch="discard");
Calculate the total number of iterations for the training progress monitor.
numObservationsTrain = numel(imdsTrain.Files); numIterationsPerEpoch = floor(numObservationsTrain / miniBatchSize); numIterations = numEpochs * numIterationsPerEpoch;
Initialize the TrainingProgressMonitor object. Because the timer starts when you create the monitor object, make sure that you create the object close to the training loop.
monitor = trainingProgressMonitor( ... Metrics="Loss", ... Info="Epoch", ... XLabel="Iteration");
Train the network using a custom training loop. For each epoch, shuffle the data and loop over mini-batches of data. For each mini-batch:
Evaluate the model loss, gradients, and state using the
dlfevalandmodelLossfunctions and update the network state.Update the network parameters using the
dlupdatefunction with the custom update function.Update the loss and epoch values in the training progress monitor.
Stop if the Stop property of the monitor is true. The Stop property value of the
TrainingProgressMonitorobject changes to true when you click the Stop button.
epoch = 0; iteration = 0; % Loop over epochs. while epoch < numEpochs && ~monitor.Stop epoch = epoch + 1; % Shuffle data. shuffle(mbq); % Loop over mini-batches. while hasdata(mbq) && ~monitor.Stop iteration = iteration + 1; % Read mini-batch of data. [X,T] = next(mbq); % Evaluate the model gradients, state, and loss using dlfeval and the % modelLoss function and update the network state. [loss,gradients,state] = dlfeval(@modelLoss,net,X,T); net.State = state; % Update the network parameters using SGD. updateFcn = @(parameters,gradients) sgdStep(parameters,gradients,learnRate); net = dlupdate(updateFcn,net,gradients); % Update the training progress monitor. recordMetrics(monitor,iteration,Loss=loss); updateInfo(monitor,Epoch=epoch); monitor.Progress = 100 * iteration/numIterations; end end
Test Model
Test the neural network using the testnet function. For single-label classification, evaluate the accuracy. The accuracy is the percentage of correct predictions. By default, the testnet function uses a GPU if one is available. To select the execution environment manually, use the ExecutionEnvironment argument of the testnet function.
accuracy = testnet(net,augimdsTest,"accuracy")accuracy = 96.3000
Visualize the predictions in a confusion chart. Make predictions using the minibatchpredict function, and convert the classification scores to labels using the scores2label function. By default, the minibatchpredict function uses a GPU if one is available. To select the execution environment manually, use the ExecutionEnvironment argument of the minibatchpredict function.
scores = minibatchpredict(net,augimdsTest); YTest = scores2label(scores,classes);
Visualize the predictions in a confusion chart.
TTest = imdsTest.Labels; figure confusionchart(TTest,YTest)
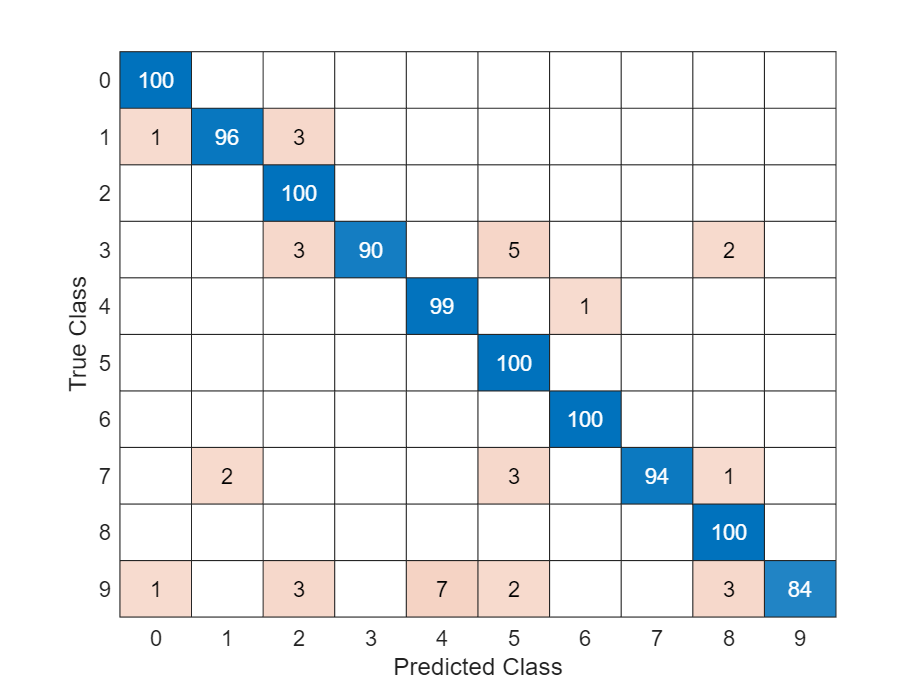
Large values on the diagonal indicate accurate predictions for the corresponding class. Large values on the off-diagonal indicate strong confusion between the corresponding classes.
Supporting Functions
Mini Batch Preprocessing Function
The preprocessMiniBatch function preprocesses a mini-batch of predictors and labels using the following steps:
Preprocess the images using the
preprocessMiniBatchPredictorsfunction.Extract the label data from the incoming cell array and concatenate into a categorical array along the second dimension.
One-hot encode the categorical labels into numeric arrays. Encoding into the first dimension produces an encoded array that matches the shape of the network output.
function [X,T] = preprocessMiniBatch(dataX,dataT) % Preprocess predictors. X = preprocessMiniBatchPredictors(dataX); % Extract label data from cell and concatenate. T = cat(2,dataT{:}); % One-hot encode labels. T = onehotencode(T,1); end
Mini-Batch Predictors Preprocessing Function
The preprocessMiniBatchPredictors function preprocesses a mini-batch of predictors by extracting the image data from the input cell array and concatenate into a numeric array. For grayscale input, concatenating over the fourth dimension adds a third dimension to each image, to use as a singleton channel dimension.
function X = preprocessMiniBatchPredictors(dataX) % Concatenate. X = cat(4,dataX{:}); end
See Also
trainingProgressMonitor | dlarray | dlgradient | dlfeval | dlnetwork | forward | adamupdate | predict | minibatchqueue | onehotencode | onehotdecode
Topics
- Custom Loss Functions
- Custom Training Loops
- Custom Training Loop Model Loss Functions
- Train Generative Adversarial Network (GAN)
- Update Batch Normalization Statistics in Custom Training Loop
- Specify Training Options in Custom Training Loop
- Monitor Custom Training Loop Progress
- List of Deep Learning Layers
- List of Functions with dlarray Support