Provide LQR Performance Using Terminal Penalty Weights
It is possible to make a finite-horizon model predictive controller equivalent to an infinite-horizon linear quadratic regulator (LQR) by setting tuning weights on the terminal predicted states.
The standard MPC cost function is similar to the cost function for an LQR controller with output weighting, as shown in the following equation:
.
The LQR and MPC cost functions differ in the following ways:
The LQR cost function forces and toward zero, whereas the MPC cost function forces and toward nonzero setpoints. You can shift the MPC prediction model origin to eliminate this difference and achieve zero nominal setpoints.
The LQR cost function uses an infinite prediction horizon in which the manipulated variable changes at each sample time. In the standard MPC cost function, the horizon length is , and the manipulated variable changes times, where is the control horizon.
The two cost functions are equivalent if the MPC cost function is:
.
Here, is a terminal penalty weight applied at the final prediction horizon step, and the prediction and control horizons are equal ( = ). The required is the Riccati matrix calculated using the lqr or lqry commands.
Define Plant Model
Specify the discrete-time open-loop dynamic plant model with a sample time of 0.1 seconds. For this model, make all states measurable outputs of the plant. This plant is the double integrator plant from [1].
A = [1 0;0.1 1]; B = [0.1;0.005]; C = eye(2); D = zeros(2,1); Ts = 0.1; plant = ss(A,B,C,D,Ts);
Design Infinite-Horizon LQR Controller
Compute the Riccati matrix Qp and state feedback gain K associated with the LQR problem with output weight Q and input weight R. For more information, see lqry.
Q = eye(2); R = 1; [K,Qp] = lqry(plant,Q,R);
Design Equivalent MPC Controller
To implement the MPC cost function, first compute , the Cholesky decomposition of , such that .
L = chol(Qp);
Next, define auxiliary unmeasured output variables , such that . Augment the output vector of the plant such that it includes these auxiliary outputs.
newPlant = plant; set(newPlant,'C',[C;L],'D',[D;zeros(2,1)]);
Configure the state vector outputs as measured outputs and the auxiliary output signals as unmeasured outputs. By default, the input signal is the manipulated variable.
newPlant = setmpcsignals(newPlant,'MO',[1 2],'UO',[3 4]);
Create the controller object with the same sample time as the plant and equal prediction and control horizons.
p = 3; m = p; mpcobj = mpc(newPlant,Ts,p,m);
-->"Weights.ManipulatedVariables" is empty. Assuming default 0.00000. -->"Weights.ManipulatedVariablesRate" is empty. Assuming default 0.10000. -->"Weights.OutputVariables" is empty. Assuming default 1.00000. for output(s) y1 and zero weight for output(s) y2 y3 y4
Define tuning weights at each step of the prediction horizon for the manipulated variable and the measured outputs.
ywt = sqrt(diag(Q))'; uwt = sqrt(diag(R))'; mpcobj.Weights.OV = [sqrt(diag(Q))' 0 0]; mpcobj.Weights.MV = sqrt(R);
To make the QP problem associated with the MPC controller positive definite, include very small weights on manipulated variable increments.
mpcobj.Weights.MVRate = 1e-5;
Impose the terminal penalty by specifying a unit weight on . The terminal weight on u(t+p-1) remains the same.
Y = struct('Weight',[0 0 1 1]); U = struct('Weight',uwt); setterminal(mpcobj,Y,U);
Because the measured output vector contains the entire state vector, remove any additional output disturbance integrator inserted by the MPC controller.
setoutdist(mpcobj,'model',ss(zeros(4,1)));Remove the state estimator by defining the following measurement update equation:
x[n|n] = x[n|n-1] + I * (x[n]-x[n|n-1]) = x[n]
Because the setterminal function resets the state estimator to its default value, call the setEstimator function after calling setterminal.
setEstimator(mpcobj,[],eye(2));
Compare MPC and LQR Controller Gains
Compute the gain of the MPC controller when the constraints are inactive (unconstrained MPC), and compare it to the LQR gain.
mpcgain = dcgain(ss(mpcobj));
-->"Model.Noise" is empty. Assuming white noise on each measured output.
fprintf('\n(unconstrained) MPC: u(k)=[%8.8g,%8.8g]*x(k)', ... mpcgain(1),mpcgain(2));
(unconstrained) MPC: u(k)=[-1.6355962,-0.91707456]*x(k)
fprintf('\n LQR: u(k)=[%8.8g,%8.8g]*x(k)\n\n', ... -K(1),-K(2));
LQR: u(k)=[-1.6355962,-0.91707456]*x(k)
The state feedback gains are exactly the same.
Compare Controller Performance
Compare the performance of the LQR controller, the MPC controller with terminal weights, and a standard MPC controller.
Compute the closed-loop response of the LQR controller to initial conditions x0.
clsys = feedback(plant,K); Tstop = 6; x0 = [0.2;0.2]; [yLQR,tLQR] = initial(clsys,x0,Tstop);
Compute the closed-loop response of the MPC controller with terminal weights to initial conditions x0.
simOpt = mpcsimopt(mpcobj); simOpt.PlantInitialState = x0; r = zeros(1,4); [y,t,u] = sim(mpcobj,ceil(Tstop/Ts),r,simOpt);
Create a standard MPC controller with default prediction and control horizons (p=10, m=3). To match the other controllers, remove the output disturbance model and the default state estimator from the standard MPC controller.
mpcobjSTD = mpc(plant,Ts);
-->"PredictionHorizon" is empty. Assuming default 10. -->"ControlHorizon" is empty. Assuming default 2. -->"Weights.ManipulatedVariables" is empty. Assuming default 0.00000. -->"Weights.ManipulatedVariablesRate" is empty. Assuming default 0.10000. -->"Weights.OutputVariables" is empty. Assuming default 1.00000. for output(s) y1 and zero weight for output(s) y2
mpcobjSTD.Weights.MV = uwt;
mpcobjSTD.Weights.OV = ywt;
setoutdist(mpcobjSTD,'model',tf(zeros(2,1)))
setEstimator(mpcobjSTD,[],C)Compute the closed-loop response for the standard MPC controller.
simOpt = mpcsimopt(mpcobjSTD); simOpt.PlantInitialState = x0; r = zeros(1,2); [ySTD,tSTD,uSTD] = sim(mpcobjSTD,ceil(Tstop/Ts),r,simOpt);
-->"Model.Noise" is empty. Assuming white noise on each measured output.
Compare the controller responses.
plot(tSTD,ySTD,'r',t,y(:,1:2),'b',tLQR,yLQR,'mo') xlabel('Time') ylabel('Plant Outputs') legend('Standard MPC','MPC with Terminal Weights','LQR', ... Location="NorthEast")
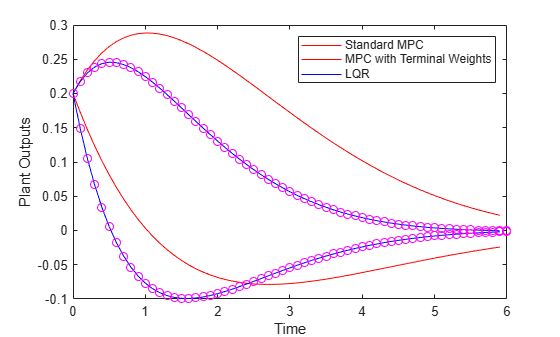
The MPC controller with terminal weights has a faster settling time compared to the standard MPC controller. The LQR controller and the MPC controller with terminal weights perform identically.
You can improve the standard MPC controller performance by adjusting the horizons. For example, if you increase the prediction and control horizons (p=20, m=5), the standard MPC controller performs almost identically to the MPC controller with terminal weights.
This example shows that using terminal penalty weights can eliminate the need to tune the prediction and control horizons for the unconstrained MPC case. If your application includes constraints, using a terminal weight is insufficient to guarantee nominal stability. You must also choose appropriate horizons and possibly add terminal constraints. For more information, see [2].
References
[1] Scokaert, P. O. M. and J. B. Rawlings, "Constrained linear quadratic regulation," IEEE Transactions on Automatic Control (1998), Vol. 43, No. 8, pp. 1163-1169.
[2] Rawlings, J. B. and D. Q. Mayne, Model Predictive Control: Theory and Design. Nob Hill Publishing, 2010.