Check Classifier Performance Using Test Data Set in Classification Learner App
This example shows how to train multiple models in the Classification Learner app, and determine the best-performing models based on their validation accuracy. Check the test accuracy for the best-performing models using the test data set.
In the MATLAB® Command Window, load the
ionospheredata set, and create a table containing the data. Separate the table into training and test data sets.load ionosphere tbl = array2table(X); tbl.Y = Y; rng("default") % For reproducibility of the data split partition = cvpartition(Y,Holdout=0.15); idxTrain = training(partition); % Indices for the training set tblTrain = tbl(idxTrain,:); tblTest = tbl(~idxTrain,:);
Alternatively, you can create a test data set later on when you import data into the app. For more information, see Test Trained Models in Classification Learner or Regression Learner.
Open Classification Learner. Click the Apps tab, and then click the arrow at the right of the Apps section to open the apps gallery. In the Machine Learning and Deep Learning group, click Classification Learner.
On the Learn tab, in the File section, select New Session > From Workspace Data.
In the New Session from Workspace Data dialog box, select the
tblTraintable from the Data Set Variable list. The app selectsYas the response variable, and selects the other variables intblTrainas predictors. To protect against overfitting, the default validation scheme is 5-fold cross-validation. For this example, do not change the default settings.To accept the default settings and continue, click Start Session.
Train all preset models. In the Models section of the Learn tab, click All. In the Train section, click Train All and select Train All. The app trains one of each preset model type, along with the default fine tree model, and displays the models in the Models pane.
Note
If you have Parallel Computing Toolbox™, then the Use Parallel button is selected by default. After you click Train All and select Train All or Train Selected, the app opens a parallel pool of workers. During this time, you cannot interact with the software. After the pool opens, you can continue to interact with the app while models train in parallel.
If you do not have Parallel Computing Toolbox, then the Use Background Training check box in the Train All menu is selected by default. After you select an option to train models, the app opens a background pool. After the pool opens, you can continue to interact with the app while models train in the background.
Sort the trained models based on the validation accuracy. In the Models pane, open the Sort by list and select
Accuracy (Validation).In the Models pane, click the star icons next to the three models with the highest validation accuracy. The app highlights the highest validation accuracy by outlining it in a box. In this example, the trained SVM Kernel model has the highest validation accuracy.

The app displays a validation confusion matrix for the second fine tree model (model 2.1). Blue values indicate correct classifications, and red values indicate incorrect classifications. The Models pane on the left shows the validation accuracy for each model.
Note
Validation introduces some randomness into the results. Your model validation results can vary from the results shown in this example.
Check the test data set performance of the best-performing models. Begin by importing test data into the app.
On the Test tab, in the Data section, click Import Test Data and select From Workspace.
In the Import Test Data dialog box, select the
tblTesttable from the Test Data Set Variable list.As shown in the dialog box, the app identifies the response and predictor variables.
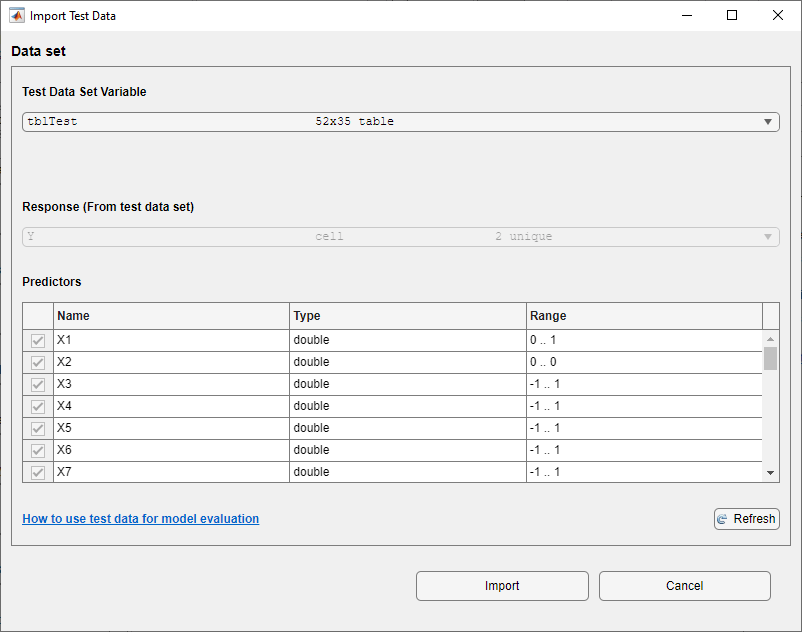
Click Import.
Compute the accuracy of the best preset models on the
tblTestdata. Select the first starred model in the Models pane. On the Test tab, in the Test section, click Test Selected. The app computes the test data set performance of the model (which was trained on the training data set).Repeat the previous step for the other two starred models. Close the Testing Multiple Models dialog box each time by clicking OK (or select the check box in the dialog box to hide it for the rest of the app session).
Sort the models based on the test data set accuracy. In the Models pane, open the Sort by list and select
Accuracy (Test). The app still outlines the metric for the model with the highest validation accuracy, despite displaying the test accuracy.Visually check the test data set performance of the models. For each starred model, select the model in the Models pane. On the Test tab, in the Plots and Results section, click Confusion Matrix (Test).
Rearrange the layout of the plots to better compare them. First, close the summary and plot tabs for Model 1 and Model 2.1. Then, click the Document Actions button
 located to the far right of the model plot tabs. Select the
located to the far right of the model plot tabs. Select the
Tile Alloption and specify a 1-by-3 layout. Click the Hide plot options button at the top right of the plots to make more
room for the plots.
at the top right of the plots to make more
room for the plots.In this example, the trained Medium Gaussian SVM model is the best-performing model on the test data set.

To return to the original layout, you can click the Layout button in the Plots and Results section and select Single model (Default).
Compare the validation and test accuracy for the trained SVM Kernel model. In the Models pane, double-click the model. In the model Summary tab, compare the Accuracy (Validation) value under Training Results to the Accuracy (Test) value under Test Results. In this example, the validation accuracy is higher than the test accuracy, which indicates that the validation accuracy is perhaps overestimating the performance of this model.