fitrgam
Fit generalized additive model (GAM) for regression
Syntax
Description
Mdl = fitrgam(Tbl,ResponseVarName)Mdl trained using the sample data contained in the table
Tbl. The input argument ResponseVarName is the
name of the variable in Tbl that contains the response values for
regression.
Mdl = fitrgam(___,Name,Value)'Interactions',5 specifies to include five interaction terms in the
model. You can also specify a list of interaction terms using the
'Interactions' name-value argument.
[
also returns Mdl,AggregateOptimizationResults] = fitrgam(___)AggregateOptimizationResults, which contains
hyperparameter optimization results when you specify the
OptimizeHyperparameters and
HyperparameterOptimizationOptions name-value arguments. You must
also specify the ConstraintType and
ConstraintBounds options of
HyperparameterOptimizationOptions. You can use this syntax to
optimize on compact model size instead of cross-validation loss, and to perform a set of
multiple optimization problems that have the same options but different constraint
bounds.
Examples
Train a univariate GAM, which contains linear terms for predictors. Then, interpret the prediction for a specified data instance by using the plotLocalEffects function.
Load the data set NYCHousing2015.
load NYCHousing2015The data set includes 10 variables with information on the sales of properties in New York City in 2015. This example uses these variables to analyze the sale prices (SALEPRICE).
Preprocess the data set. Remove outliers, convert the datetime array (SALEDATE) to the month numbers, and move the response variable (SALEPRICE) to the last column.
idx = isoutlier(NYCHousing2015.SALEPRICE); NYCHousing2015(idx,:) = []; NYCHousing2015.SALEDATE = month(NYCHousing2015.SALEDATE); NYCHousing2015 = movevars(NYCHousing2015,'SALEPRICE','After','SALEDATE');
Display the first three rows of the table.
head(NYCHousing2015,3)
BOROUGH NEIGHBORHOOD BUILDINGCLASSCATEGORY RESIDENTIALUNITS COMMERCIALUNITS LANDSQUAREFEET GROSSSQUAREFEET YEARBUILT SALEDATE SALEPRICE
_______ ____________ ____________________________ ________________ _______________ ______________ _______________ _________ ________ _________
2 {'BATHGATE'} {'01 ONE FAMILY DWELLINGS'} 1 0 4750 2619 1899 8 0
2 {'BATHGATE'} {'01 ONE FAMILY DWELLINGS'} 1 0 4750 2619 1899 8 0
2 {'BATHGATE'} {'01 ONE FAMILY DWELLINGS'} 1 1 1287 2528 1899 12 0
Train a univariate GAM for the sale prices. Specify the variables for BOROUGH, NEIGHBORHOOD, BUILDINGCLASSCATEGORY, and SALEDATE as categorical predictors.
Mdl = fitrgam(NYCHousing2015,'SALEPRICE','CategoricalPredictors',[1 2 3 9])
Mdl =
RegressionGAM
PredictorNames: {'BOROUGH' 'NEIGHBORHOOD' 'BUILDINGCLASSCATEGORY' 'RESIDENTIALUNITS' 'COMMERCIALUNITS' 'LANDSQUAREFEET' 'GROSSSQUAREFEET' 'YEARBUILT' 'SALEDATE'}
ResponseName: 'SALEPRICE'
CategoricalPredictors: [1 2 3 9]
ResponseTransform: 'none'
Intercept: 3.7518e+05
IsStandardDeviationFit: 0
NumObservations: 83517
Properties, Methods
Mdl is a RegressionGAM model object. The model display shows a partial list of the model properties. To view the full list of properties, double-click the variable name Mdl in the Workspace. The Variables editor opens for Mdl. Alternatively, you can display the properties in the Command Window by using dot notation. For example, display the estimated intercept (constant) term of Mdl.
Mdl.Intercept
ans = 3.7518e+05
Predict the sale price for the first observation of the training data, and plot the local effects of the terms in Mdl on the prediction.
yFit = predict(Mdl,NYCHousing2015(1,:))
yFit = 4.4421e+05
plotLocalEffects(Mdl,NYCHousing2015(1,:))
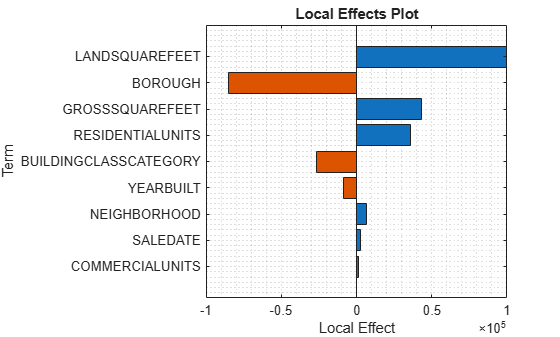
The predict function predicts the sale price for the first observation as 4.4421e5. The plotLocalEffects function creates a horizontal bar graph that shows the local effects of the terms in Mdl on the prediction. Each local effect value shows the contribution of each term to the predicted sale price.
Train a generalized additive model that contains linear and interaction terms for predictors in three different ways:
Specify the interaction terms using the
formulainput argument.Specify the
'Interactions'name-value argument.Build a model with linear terms first and add interaction terms to the model by using the
addInteractionsfunction.
Load the carbig data set, which contains measurements of cars made in the 1970s and early 1980s.
load carbigCreate a table that contains the predictor variables (Acceleration, Displacement, Horsepower, and Weight) and the response variable (MPG).
tbl = table(Acceleration,Displacement,Horsepower,Weight,MPG);
Specify formula
Train a GAM that contains the four linear terms (Acceleration, Displacement, Horsepower, and Weight) and two interaction terms (Acceleration*Displacement and Displacement*Horsepower). Specify the terms using a formula in the form 'Y ~ terms'.
Mdl1 = fitrgam(tbl,'MPG ~ Acceleration + Displacement + Horsepower + Weight + Acceleration:Displacement + Displacement:Horsepower');The function adds interaction terms to the model in the order of importance. You can use the Interactions property to check the interaction terms in the model and the order in which fitrgam adds them to the model. Display the Interactions property.
Mdl1.Interactions
ans = 2×2
2 3
1 2
Each row of Interactions represents one interaction term and contains the column indexes of the predictor variables for the interaction term.
Specify 'Interactions'
Pass the training data (tbl) and the name of the response variable in tbl to fitrgam, so that the function includes the linear terms for all the other variables as predictors. Specify the 'Interactions' name-value argument using a logical matrix to include the two interaction terms, x1*x2 and x2*x3.
Mdl2 = fitrgam(tbl,'MPG','Interactions',logical([1 1 0 0; 0 1 1 0])); Mdl2.Interactions
ans = 2×2
2 3
1 2
You can also specify 'Interactions' as the number of interaction terms or as 'all' to include all available interaction terms. Among the specified interaction terms, fitrgam identifies those whose p-values are not greater than the 'MaxPValue' value and adds them to the model. The default 'MaxPValue' is 1 so that the function adds all specified interaction terms to the model.
Specify 'Interactions','all' and set the 'MaxPValue' name-value argument to 0.05.
Mdl3 = fitrgam(tbl,'MPG','Interactions','all','MaxPValue',0.05);
Warning: Model does not include interaction terms because all interaction terms have p-values greater than the 'MaxPValue' value, or the software was unable to improve the model fit.
Mdl3.Interactions
ans = 0×2 empty double matrix
Mdl3 includes no interaction terms, which implies one of the following: all interaction terms have p-values greater than 0.05, or adding the interaction terms does not improve the model fit.
Use addInteractions Function
Train a univariate GAM that contains linear terms for predictors, and then add interaction terms to the trained model by using the addInteractions function. Specify the second input argument of addInteractions in the same way you specify the 'Interactions' name-value argument of fitrgam. You can specify the list of interaction terms using a logical matrix, the number of interaction terms, or 'all'.
Specify the number of interaction terms as 3 to add the three most important interaction terms to the trained model.
Mdl4 = fitrgam(tbl,'MPG');
UpdatedMdl4 = addInteractions(Mdl4,3);
UpdatedMdl4.Interactionsans = 3×2
2 3
1 2
3 4
Mdl4 is a univariate GAM, and UpdatedMdl4 is an updated GAM that contains all the terms in Mdl4 and three additional interaction terms.
Train a cross-validated GAM with 10 folds, which is the default cross-validation option, by using fitrgam. Then, use kfoldPredict to predict responses for validation-fold observations using a model trained on training-fold observations.
Load the carbig data set, which contains measurements of cars made in the 1970s and early 1980s.
load carbigCreate a table that contains the predictor variables (Acceleration, Displacement, Horsepower, and Weight) and the response variable (MPG).
tbl = table(Acceleration,Displacement,Horsepower,Weight,MPG);
Create a cross-validated GAM by using the default cross-validation option. Specify the 'CrossVal' name-value argument as 'on'.
rng('default') % For reproducibility CVMdl = fitrgam(tbl,'MPG','CrossVal','on')
CVMdl =
RegressionPartitionedGAM
CrossValidatedModel: 'GAM'
PredictorNames: {'Acceleration' 'Displacement' 'Horsepower' 'Weight'}
ResponseName: 'MPG'
NumObservations: 398
KFold: 10
Partition: [1×1 cvpartition]
NumTrainedPerFold: [1×1 struct]
ResponseTransform: 'none'
IsStandardDeviationFit: 0
Properties, Methods
The fitrgam function creates a RegressionPartitionedGAM model object CVMdl with 10 folds. During cross-validation, the software completes these steps:
Randomly partition the data into 10 sets.
For each set, reserve the set as validation data, and train the model using the other 9 sets.
Store the 10 compact, trained models a in a 10-by-1 cell vector in the
Trainedproperty of the cross-validated model objectRegressionPartitionedGAM.
You can override the default cross-validation setting by using the 'CVPartition', 'Holdout', 'KFold', or 'Leaveout' name-value argument.
Predict responses for the observations in tbl by using kfoldPredict. The function predicts responses for every observation using the model trained without that observation.
yHat = kfoldPredict(CVMdl);
yHat is a numeric vector. Display the first five predicted responses.
yHat(1:5)
ans = 5×1
19.4848
15.7203
15.5742
15.3185
17.8223
Compute the regression loss (mean squared error).
L = kfoldLoss(CVMdl)
L = 17.7248
kfoldLoss returns the average mean squared error over 10 folds.
Optimize the hyperparameters of a GAM with respect to cross-validation by using the OptimizeHyperparameters name-value argument.
Load the carbig data set, which contains measurements of cars made in the 1970s and early 1980s.
load carbigSpecify Acceleration, Displacement, Horsepower, and Weight as the predictor variables (X) and MPG as the response variable (Y).
X = [Acceleration,Displacement,Horsepower,Weight]; Y = MPG;
Partition the data into training and test sets. Use approximately 80% of the observations to train a model, and 20% of the observations to test the performance of the trained model on new data. Use cvpartition to partition the data.
rng("default") % For reproducibility cvp = cvpartition(length(MPG),Holdout=0.20); XTrain = X(training(cvp),:); YTrain = Y(training(cvp)); XTest = X(test(cvp),:); YTest = Y(test(cvp));
Train a GAM for regression by passing the training data to the fitrgam function, and include the OptimizeHyperparameters argument. Specify OptimizeHyperparameters as "auto" so that fitrgam finds optimal values of InitialLearnRateForPredictors, NumTreesPerPredictor, Interactions, InitialLearnRateForInteractions, and NumTreesPerInteraction. For reproducibility, choose the "expected-improvement-plus" acquisition function. The default acquisition function depends on run time and, therefore, can give varying results.
rng("default") Mdl = fitrgam(XTrain,YTrain,OptimizeHyperparameters="auto", ... HyperparameterOptimizationOptions= ... struct(AcquisitionFunctionName="expected-improvement-plus"))
|==========================================================================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | InitialLearnRate-| NumTreesPerP-| Interactions | InitialLearnRate-| NumTreesPerI-|
| | result | log(1+loss) | runtime | (observed) | (estim.) | ForPredictors | redictor | | ForInteractions | nteraction |
|==========================================================================================================================================================|
| 1 | Best | 2.874 | 2.9323 | 2.874 | 2.874 | 0.21533 | 500 | 1 | 0.35042 | 13 |
| 2 | Accept | 2.89 | 0.11683 | 2.874 | 2.8748 | 0.062841 | 14 | 1 | 0.014907 | 10 |
| 3 | Accept | 3.3298 | 1.3031 | 2.874 | 2.8746 | 0.001387 | 222 | 0 | - | - |
| 4 | Best | 2.8562 | 4.1094 | 2.8562 | 2.8564 | 0.08216 | 434 | 4 | 0.14875 | 283 |
| 5 | Accept | 2.976 | 1.2708 | 2.8562 | 2.8564 | 0.99942 | 217 | 1 | 0.0017491 | 34 |
| 6 | Best | 2.8195 | 0.91725 | 2.8195 | 2.8198 | 0.13778 | 152 | 6 | 0.012566 | 13 |
| 7 | Best | 2.7519 | 0.68161 | 2.7519 | 2.752 | 0.12531 | 42 | 4 | 0.27647 | 53 |
| 8 | Best | 2.7301 | 2.7319 | 2.7301 | 2.7301 | 0.18671 | 10 | 3 | 0.0063418 | 487 |
| 9 | Best | 2.7196 | 0.35104 | 2.7196 | 2.7196 | 0.13792 | 10 | 5 | 0.1663 | 27 |
| 10 | Accept | 2.8281 | 2.4454 | 2.7196 | 2.7196 | 0.23324 | 10 | 4 | 0.75904 | 314 |
| 11 | Accept | 2.7864 | 0.15438 | 2.7196 | 2.7196 | 0.13035 | 10 | 1 | 0.30171 | 476 |
| 12 | Accept | 2.7993 | 0.46166 | 2.7196 | 2.7647 | 0.16476 | 10 | 6 | 0.015498 | 32 |
| 13 | Accept | 2.7847 | 2.8541 | 2.7196 | 2.7197 | 0.0090953 | 499 | 5 | 0.027878 | 40 |
| 14 | Accept | 3.5847 | 0.1682 | 2.7196 | 2.7592 | 0.0035123 | 11 | 3 | 0.011127 | 11 |
| 15 | Accept | 2.7237 | 3.1766 | 2.7196 | 2.759 | 0.015848 | 498 | 3 | 0.14359 | 238 |
| 16 | Accept | 2.779 | 1.2179 | 2.7196 | 2.7588 | 0.012829 | 10 | 3 | 0.028814 | 217 |
| 17 | Accept | 2.7761 | 2.5403 | 2.7196 | 2.7272 | 0.023165 | 488 | 1 | 0.32642 | 302 |
| 18 | Accept | 2.8604 | 2.7672 | 2.7196 | 2.7677 | 0.013548 | 495 | 2 | 0.97963 | 141 |
| 19 | Accept | 3.5466 | 0.087554 | 2.7196 | 2.7196 | 0.019794 | 10 | 0 | - | - |
| 20 | Accept | 2.7513 | 6.0349 | 2.7196 | 2.7196 | 0.02408 | 62 | 6 | 0.023502 | 490 |
|==========================================================================================================================================================|
| Iter | Eval | Objective: | Objective | BestSoFar | BestSoFar | InitialLearnRate-| NumTreesPerP-| Interactions | InitialLearnRate-| NumTreesPerI-|
| | result | log(1+loss) | runtime | (observed) | (estim.) | ForPredictors | redictor | | ForInteractions | nteraction |
|==========================================================================================================================================================|
| 21 | Accept | 2.7243 | 0.70792 | 2.7196 | 2.7196 | 0.040761 | 11 | 3 | 0.10556 | 120 |
| 22 | Best | 2.6969 | 3.4022 | 2.6969 | 2.697 | 0.0032557 | 494 | 2 | 0.039381 | 487 |
| 23 | Accept | 2.8184 | 3.0333 | 2.6969 | 2.697 | 0.0072249 | 19 | 3 | 0.27653 | 494 |
| 24 | Accept | 2.7788 | 2.9065 | 2.6969 | 2.697 | 0.0064015 | 482 | 1 | 0.013479 | 479 |
| 25 | Accept | 2.7646 | 2.9407 | 2.6969 | 2.6971 | 0.0013222 | 473 | 2 | 0.17272 | 436 |
| 26 | Accept | 2.8368 | 0.19526 | 2.6969 | 2.6971 | 0.93418 | 11 | 5 | 0.16983 | 11 |
| 27 | Accept | 2.7724 | 1.3361 | 2.6969 | 2.6971 | 0.039216 | 11 | 2 | 0.037865 | 480 |
| 28 | Accept | 2.8795 | 0.61814 | 2.6969 | 2.6971 | 0.73103 | 11 | 1 | 0.014567 | 480 |
| 29 | Accept | 2.782 | 2.5852 | 2.6969 | 2.7267 | 0.0047632 | 493 | 1 | 0.069346 | 247 |
| 30 | Accept | 2.7734 | 0.66761 | 2.6969 | 2.7297 | 0.038679 | 103 | 1 | 0.052986 | 68 |
__________________________________________________________
Optimization completed.
MaxObjectiveEvaluations of 30 reached.
Total function evaluations: 30
Total elapsed time: 65.0774 seconds
Total objective function evaluation time: 54.7154
Best observed feasible point:
InitialLearnRateForPredictors NumTreesPerPredictor Interactions InitialLearnRateForInteractions NumTreesPerInteraction
_____________________________ ____________________ ____________ _______________________________ ______________________
0.0032557 494 2 0.039381 487
Observed objective function value = 2.6969
Estimated objective function value = 2.7297
Function evaluation time = 3.4022
Best estimated feasible point (according to models):
InitialLearnRateForPredictors NumTreesPerPredictor Interactions InitialLearnRateForInteractions NumTreesPerInteraction
_____________________________ ____________________ ____________ _______________________________ ______________________
0.0032557 494 2 0.039381 487
Estimated objective function value = 2.7297
Estimated function evaluation time = 3.3957
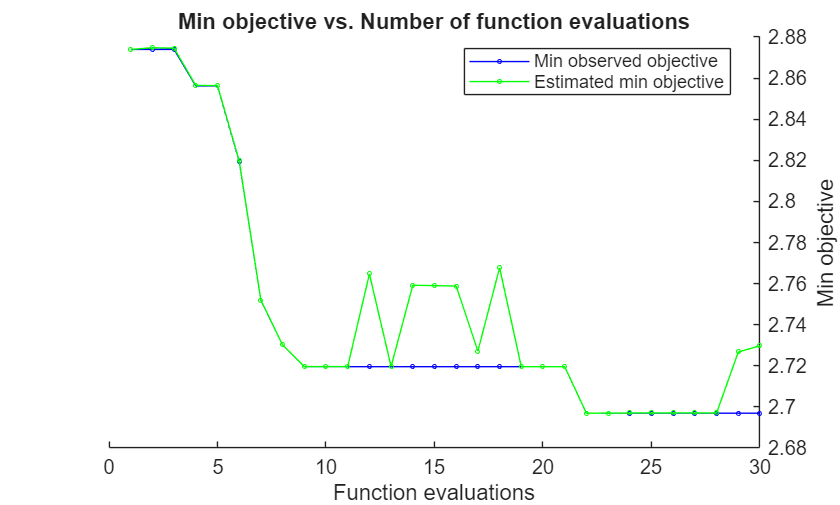
Mdl =
RegressionGAM
ResponseName: 'Y'
CategoricalPredictors: []
ResponseTransform: 'none'
Intercept: 23.7405
Interactions: [2×2 double]
IsStandardDeviationFit: 0
NumObservations: 318
HyperparameterOptimizationResults: [1×1 classreg.learning.paramoptim.SupervisedLearningBayesianOptimization]
Properties, Methods
fitrgam returns a RegressionGAM model object that uses the best estimated feasible point. The best estimated feasible point is the set of hyperparameters that minimizes the upper confidence bound of the cross-validation loss (mean squared error, MSE) based on the underlying Gaussian process model of the Bayesian optimization process.
The Bayesian optimization process internally maintains a Gaussian process model of the objective function. The objective function is log(1 + cross-validation MSE) for regression. For each iteration, the optimization process updates the Gaussian process model and uses the model to find a new set of hyperparameters. Each line of the iterative display shows the new set of hyperparameters and these column values:
Objective— Objective function value computed at the new set of hyperparameters.Objective runtime— Objective function evaluation time.Eval result— Result report, specified asAccept,Best, orError.Acceptindicates that the objective function returns a finite value, andErrorindicates that the objective function returns a value that is not a finite real scalar.Bestindicates that the objective function returns a finite value that is lower than previously computed objective function values.BestSoFar(observed)— The minimum objective function value computed so far. This value is either the objective function value of the current iteration (if theEval resultvalue for the current iteration isBest) or the value of the previousBestiteration.BestSoFar(estim.)— At each iteration, the software estimates the upper confidence bounds of the objective function values, using the updated Gaussian process model, at all the sets of hyperparameters tried so far. Then the software chooses the point with the minimum upper confidence bound. TheBestSoFar(estim.)value is the objective function value returned by thepredictObjectivefunction at the minimum point.
The plot below the iterative display shows the BestSoFar(observed) and BestSoFar(estim.) values in blue and green, respectively.
The returned object Mdl uses the best estimated feasible point, that is, the set of hyperparameters that produces the BestSoFar(estim.) value in the final iteration based on the final Gaussian process model.
Obtain the best estimated feasible point from Mdl in the HyperparameterOptimizationResults property.
Mdl.HyperparameterOptimizationResults.XAtMinEstimatedObjective
ans=1×5 table
InitialLearnRateForPredictors NumTreesPerPredictor Interactions InitialLearnRateForInteractions NumTreesPerInteraction
_____________________________ ____________________ ____________ _______________________________ ______________________
0.0032557 494 2 0.039381 487
Alternatively, you can use the bestPoint function. By default, the bestPoint function uses the "min-visited-upper-confidence-interval" criterion.
[x,CriterionValue,iteration] = bestPoint(Mdl.HyperparameterOptimizationResults)
x=1×5 table
InitialLearnRateForPredictors NumTreesPerPredictor Interactions InitialLearnRateForInteractions NumTreesPerInteraction
_____________________________ ____________________ ____________ _______________________________ ______________________
0.0032557 494 2 0.039381 487
CriterionValue = 2.7908
iteration = 22
You can also extract the best observed feasible point (that is, the last Best point in the iterative display) from the HyperparameterOptimizationResults property or by specifying Criterion as "min-observed".
Mdl.HyperparameterOptimizationResults.XAtMinObjective
ans=1×5 table
InitialLearnRateForPredictors NumTreesPerPredictor Interactions InitialLearnRateForInteractions NumTreesPerInteraction
_____________________________ ____________________ ____________ _______________________________ ______________________
0.0032557 494 2 0.039381 487
[x_observed,CriterionValue_observed,iteration_observed] = ... bestPoint(Mdl.HyperparameterOptimizationResults,Criterion="min-observed")
x_observed=1×5 table
InitialLearnRateForPredictors NumTreesPerPredictor Interactions InitialLearnRateForInteractions NumTreesPerInteraction
_____________________________ ____________________ ____________ _______________________________ ______________________
0.0032557 494 2 0.039381 487
CriterionValue_observed = 2.6969
iteration_observed = 22
In this example, the two criteria choose the same set (22nd iteration) of hyperparameters as the best point. The criterion value of each is different because CriterionValue is the upper bound of the objective function value computed by the final Gaussian process model, and CriterionValue_observed is the actual objective function value computed using the selected hyperparameters. For more information, see the Criterion name-value argument of bestPoint.
Evaluate the performance of the regression model on the training set and test set by computing the mean squared errors (MSEs). Smaller MSE values indicate better performance.
LTraining = resubLoss(Mdl)
LTraining = 6.2224
LTest = loss(Mdl,XTest,YTest)
LTest = 18.5724
Optimize the parameters of a GAM with respect to cross-validation by using the bayesopt function.
Alternatively, you can find optimal values of fitrgam name-value arguments by using the OptimizeHyperparameters name-value argument. For an example, see Optimize GAM Using OptimizeHyperparameters.
Load the carbig data set, which contains measurements of cars made in the 1970s and early 1980s.
load carbigSpecify Acceleration, Displacement, Horsepower, and Weight as the predictor variables (X) and MPG as the response variable (Y).
X = [Acceleration,Displacement,Horsepower,Weight]; Y = MPG;
You must remove the observations with missing response values to fix the cross-validation sets for the optimization process. Remove missing values from the response variable, and remove the corresponding observations in the predictor variables.
[Y,TF] = rmmissing(Y); X = X(~TF);
Set up a partition for cross-validation. This step fixes the cross-validation sets that the optimization uses at each step.
c = cvpartition(length(Y),'KFold',5);Prepare optimizableVariable objects for the name-value arguments that you want to optimize using Bayesian optimization. This example finds optimal values for the MaxNumSplitsPerPredictor and NumTreesPerPredictor arguments of fitrgam.
maxNumSplits = optimizableVariable('maxNumSplits',[1,10],'Type','integer'); numTrees = optimizableVariable('numTrees',[1,500],'Type','integer');
Create an objective function that takes an input z = [maxNumSplits,numTrees] and returns the cross-validated loss value of z.
minfun = @(z)kfoldLoss(fitrgam(X,Y,'CVPartition',c, ... 'MaxNumSplitsPerPredictor',z.maxNumSplits, ... 'NumTreesPerPredictor',z.numTrees));
If you specify a cross-validation option, then the fitrgam function returns a cross-validated model object RegressionPartitionedGAM. The kfoldLoss function returns the regression loss (mean squared error) obtained by the cross-validated model. Therefore, the function handle minfun computes the cross-validation loss at the parameters in z.
Search for the best parameters [maxNumSplits,numTrees] using bayesopt. For reproducibility, choose the 'expected-improvement-plus' acquisition function. The default acquisition function depends on run time and, therefore, can give varying results.
rng('default') results = bayesopt(minfun,[maxNumSplits,numTrees],'Verbose',0, ... 'IsObjectiveDeterministic',true, ... 'AcquisitionFunctionName','expected-improvement-plus');
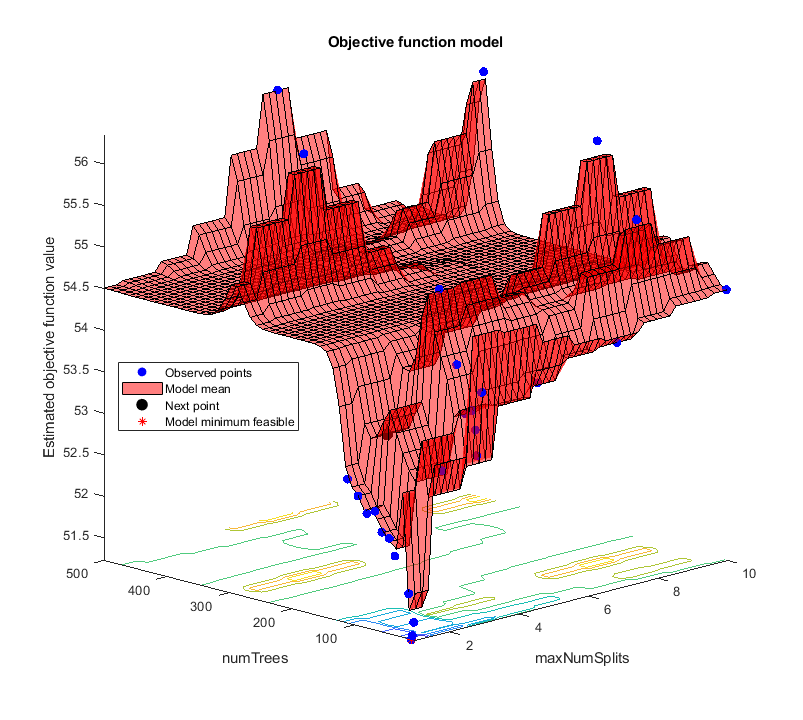
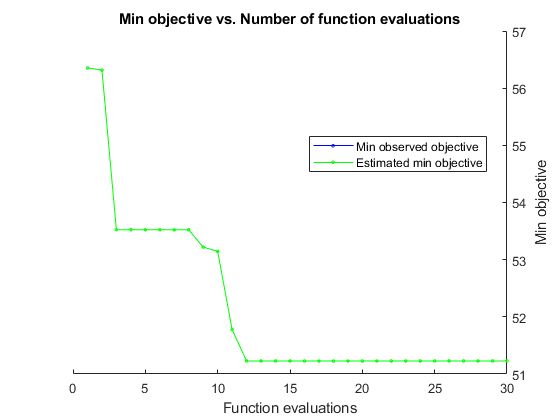
Obtain the best point from results.
zbest = bestPoint(results)
zbest=1×2 table
maxNumSplits numTrees
____________ ________
1 8
Train an optimized GAM using the zbest values.
Mdl = fitrgam(X,Y, ... 'MaxNumSplitsPerPredictor',zbest.maxNumSplits, ... 'NumTreesPerPredictor',zbest.numTrees);