ksdensity
Kernel smoothing function estimate for univariate and bivariate data
Syntax
Description
[ returns a probability
density estimate, f,xi]
= ksdensity(x)f, for the sample data in the
vector or two-column matrix x. The estimate is
based on a normal kernel function, and is evaluated at equally-spaced
points, xi, that cover the range of the data
in x. ksdensity estimates
the density at 100 points for univariate data, or 900 points for bivariate
data.
ksdensity works best with continuously
distributed samples.
[
uses additional options specified by one or more name-value pair arguments in
addition to any of the input arguments in the previous syntaxes. For example,
you can define the function type f,xi]
= ksdensity(___,Name,Value)ksdensity evaluates, such
as probability density, cumulative probability, survivor function, and so on. Or
you can specify the bandwidth of the smoothing window.
Examples
Load the sample data.
load carsmall;The variable MPG contains data for car mileage.
Generate a kernel probability density estimate for MPG.
[f,xi] = ksdensity(MPG);
f and xi contain the values and evaluation points for the kernel density estimation. By default, ksdensity uses a normal kernel smoothing function and optimal bandwidth for estimating normal densities.
Plot the estimated density.
plot(xi,f);
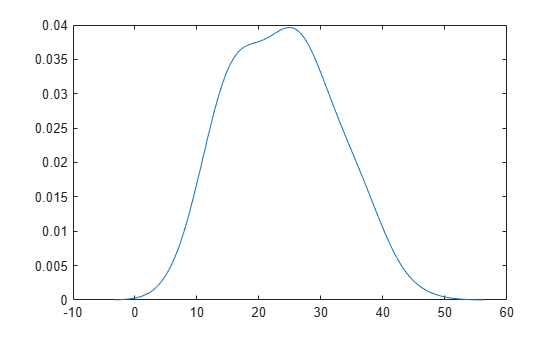
The plot shows the pdf of the kernel distribution fit to the MPG data across all makes of cars. The distribution is smooth and slightly skewed with a heavier right tail.
Generate a nonnegative sample data set from the half-normal distribution.
rng('default') % For reproducibility pd = makedist('HalfNormal','mu',0,'sigma',1); x = random(pd,100,1);
Estimate pdfs with two different boundary correction methods, log transformation and reflection, by using the 'BoundaryCorrection' name-value pair argument.
pts = linspace(0,5,1000); % points to evaluate the estimator [f1,xi1] = ksdensity(x,pts,'Support','positive'); [f2,xi2] = ksdensity(x,pts,'Support','positive','BoundaryCorrection','reflection');
Plot the two estimated pdfs.
plot(xi1,f1,xi2,f2) lgd = legend('log','reflection'); title(lgd, 'Boundary Correction Method') xl = xlim; xlim([xl(1)-0.25 xl(2)])
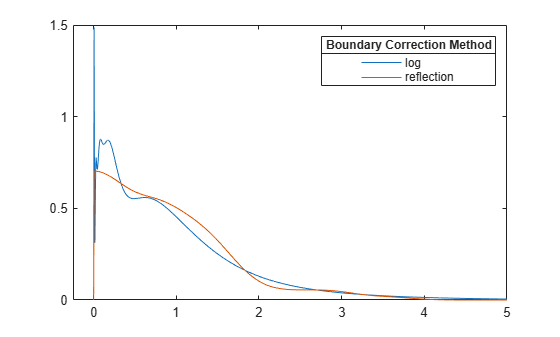
ksdensity uses a boundary correction method when you specify either positive or bounded support. The default boundary correction method is log transformation. When ksdensity transforms the support back, it introduces the 1/x term in the kernel density estimator. Therefore, the estimate has a peak near x = 0. On the other hand, the reflection method does not cause undesirable peaks near the boundary.
Load the sample data.
load hospitalCompute and plot the estimated cdf evaluated at a specified set of values.
pts = (min(hospital.Weight):2:max(hospital.Weight)); figure() ecdf(hospital.Weight) hold on [f,xi,bw] = ksdensity(hospital.Weight,pts,'Support','positive',... 'Function','cdf'); plot(xi,f,'-g','LineWidth',2) legend('empirical cdf','kernel-bw:default','Location','northwest') xlabel('Patient weights') ylabel('Estimated cdf')

ksdensity seems to smooth the cumulative distribution function estimate too much. An estimate with a smaller bandwidth might produce a closer estimate to the empirical cumulative distribution function.
Return the bandwidth of the smoothing window.
bw
bw = 0.1070
Plot the cumulative distribution function estimate using a smaller bandwidth.
[f,xi] = ksdensity(hospital.Weight,pts,'Support','positive',... 'Function','cdf','Bandwidth',0.05); plot(xi,f,'--r','LineWidth',2) legend('empirical cdf','kernel-bw:default','kernel-bw:0.05',... 'Location','northwest') hold off
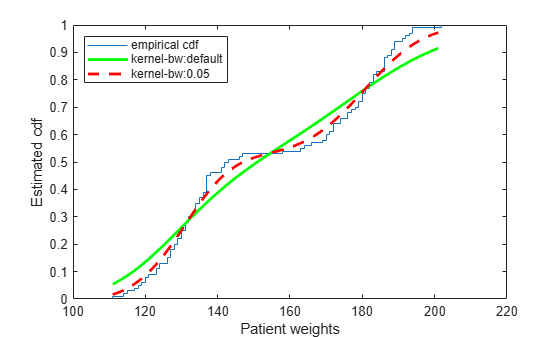
The ksdensity estimate with a smaller bandwidth matches the empirical cumulative distribution function better.
Load the sample data.
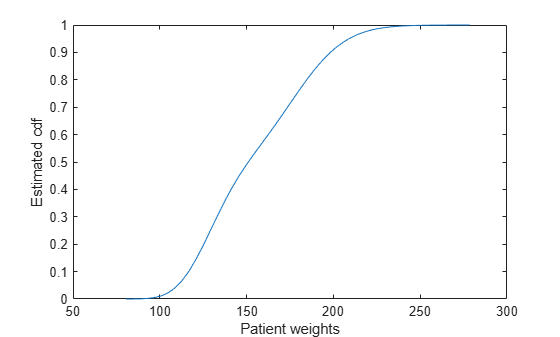
load hospitalPlot the estimated cdf evaluated at 50 equally spaced points.
figure() ksdensity(hospital.Weight,'Support','positive','Function','cdf',... 'NumPoints',50) xlabel('Patient weights') ylabel('Estimated cdf')
Generate sample data from an exponential distribution with mean 3.
rng('default') % For reproducibility x = random('exp',3,100,1);
Create a logical vector that indicates censoring. Here, observations with lifetimes longer than 10 are censored.
T = 10; cens = (x>T);
Compute and plot the estimated density function.
figure ksdensity(x,'Support','positive','Censoring',cens);
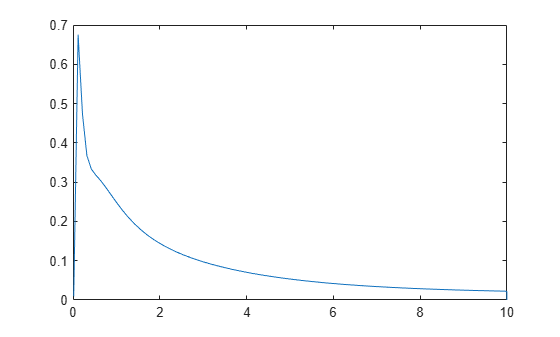
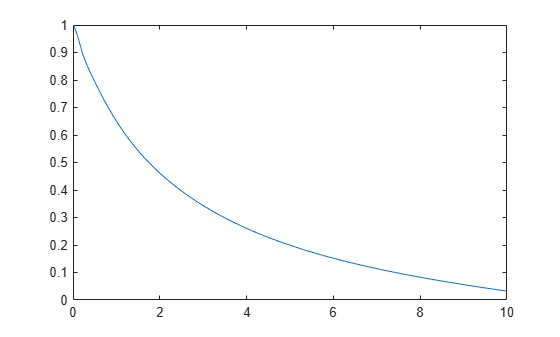
Compute and plot the survivor function.
figure ksdensity(x,'Support','positive','Censoring',cens,... 'Function','survivor');
Compute and plot the cumulative hazard function.
figure ksdensity(x,'Support','positive','Censoring',cens,... 'Function','cumhazard');

Generate a mixture of two normal distributions, and plot the estimated inverse cumulative distribution function at a specified set of probability values.
rng('default') % For reproducibility x = [randn(30,1); 5+randn(30,1)]; pi = linspace(.01,.99,99); figure ksdensity(x,pi,'Function','icdf');
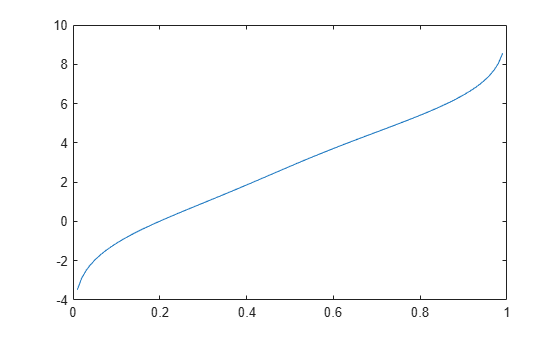
Generate a mixture of two normal distributions.
rng('default') % For reproducibility x = [randn(30,1); 5+randn(30,1)];
Return the bandwidth of the smoothing window for the probability density estimate.
[f,xi,bw] = ksdensity(x); bw
bw = 1.5141
The default bandwidth is optimal for normal densities.
Plot the estimated density.
figure plot(xi,f); xlabel('xi') ylabel('f') hold on
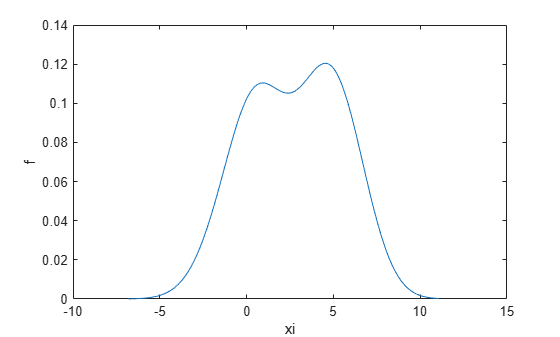
Plot the density using an increased bandwidth value.
[f,xi] = ksdensity(x,'Bandwidth',1.8); plot(xi,f,'--r','LineWidth',1.5)
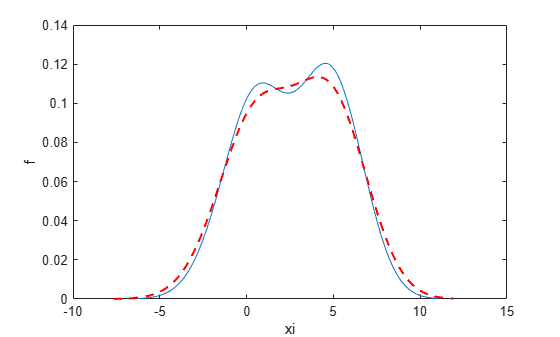
A higher bandwidth further smooths the density estimate, which might mask some characteristics of the distribution.
Now, plot the density using a decreased bandwidth value.
[f,xi] = ksdensity(x,'Bandwidth',0.8); plot(xi,f,'-.k','LineWidth',1.5) legend('bw = default','bw = 1.8','bw = 0.8') hold off
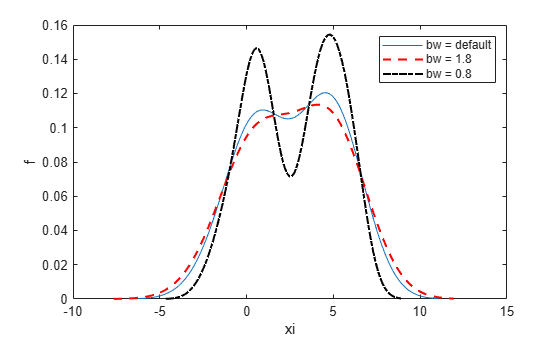
A smaller bandwidth smooths the density estimate less, which exaggerates some characteristics of the sample.
Create a two-column vector of points at which to evaluate the density.
gridx1 = -0.25:.05:1.25; gridx2 = 0:.1:15; [x1,x2] = meshgrid(gridx1, gridx2); x1 = x1(:); x2 = x2(:); xi = [x1 x2];
Generate a 30-by-2 matrix containing random numbers from a mixture of bivariate normal distributions.
rng('default') % For reproducibility x = [0+.5*rand(20,1) 5+2.5*rand(20,1); .75+.25*rand(10,1) 8.75+1.25*rand(10,1)];
Plot the estimated density of the sample data.
figure ksdensity(x,xi);
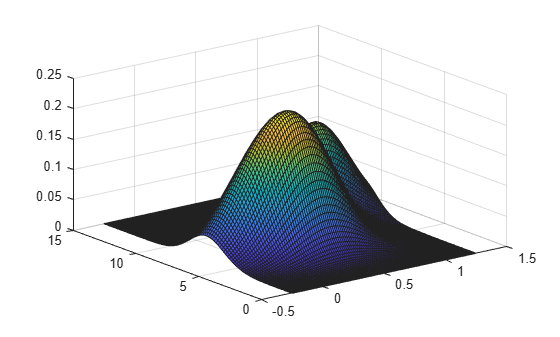
Input Arguments
Name-Value Arguments
Output Arguments
More About
Alternative Functionality
You can also estimate the pdf or cdf for univariate data by using the MATLAB®
kde
function. Unlike ksdensity, kde does not
support boundary correction methods or data censoring.
References
[1] Botev, Z. I., J. F. Grotowski, and D. P. Kroese. "Kernel Density Estimation via Diffusion." The Annals of Statistics, vol. 38, no. 5 (October 1, 2010). https://projecteuclid.org/journals/annals-of-statistics/volume-38/issue-5/Kernel-density-estimation-via-diffusion/10.1214/10-AOS799.full
[2] Bowman, A. W., and A. Azzalini. Applied Smoothing Techniques for Data Analysis. New York: Oxford University Press Inc., 1997.
[3] Hill, P. D. “Kernel estimation of a distribution function.” Communications in Statistics - Theory and Methods. Vol 14, Issue. 3, 1985, pp. 605-620.
[4] Jones, M. C. “Simple boundary correction for kernel density estimation.” Statistics and Computing. Vol. 3, Issue 3, 1993, pp. 135-146.
[5] Silverman, B. W. Density Estimation for Statistics and Data Analysis. Chapman & Hall/CRC, 1986.
Extended Capabilities
Version History
Introduced before R2006a