Quantize Residual Network Trained for Image Classification and Generate CUDA Code
This example shows how to quantize the learnable parameters in the convolution layers of a deep learning neural network that has residual connections and has been trained for image classification with CIFAR-10 data.
Neural networks use memory to store input data, parameters (weights), and activations from each layer as the input propagates through the network. Most neural networks that you create and train using Deep Learning Toolbox™ use single-precision floating point data types. Even small networks require a considerable amount of memory and hardware to perform these floating-point arithmetic operations. These restrictions can inhibit deployment of deep learning models to devices that have low computational power and less memory resources. By using a lower precision to store the weights and activations, you can reduce the memory requirements of the network.
In this example, you use the Deep Learning Toolbox in tandem with the Deep Learning Toolbox Model Compression Library support package to reduce the memory footprint of a deep neural network by quantizing the weights, biases, and activations of convolution layers to 8-bit scaled integer data types.
The network in this example has been trained for image classification with CIFAR-10 data.
Residual connections are a popular element in convolutional neural network architectures. A residual network is a type of network that has residual (or shortcut) connections that bypass the main network layers. Residual connections enable the parameter gradients to propagate more easily from the output layer to the earlier layers of the network, which makes it possible to train deeper networks. This increased network depth can result in higher accuracies on more difficult tasks. For information on the network architecture and training, see Train Residual Network for Image Classification.
To run this example, you must have the products required to quantize and deploy a deep learning network to a GPU environment. For information on these products, see Quantization Workflow System Requirements.
Load Pretrained Network
Load the pretrained network. For information on creating and training a network with residual connections for image classification yourself, see the Train Residual Network for Image Classification example.
load('CIFARNetDlNetwork.mat','trainedNet'); net = trainedNet;
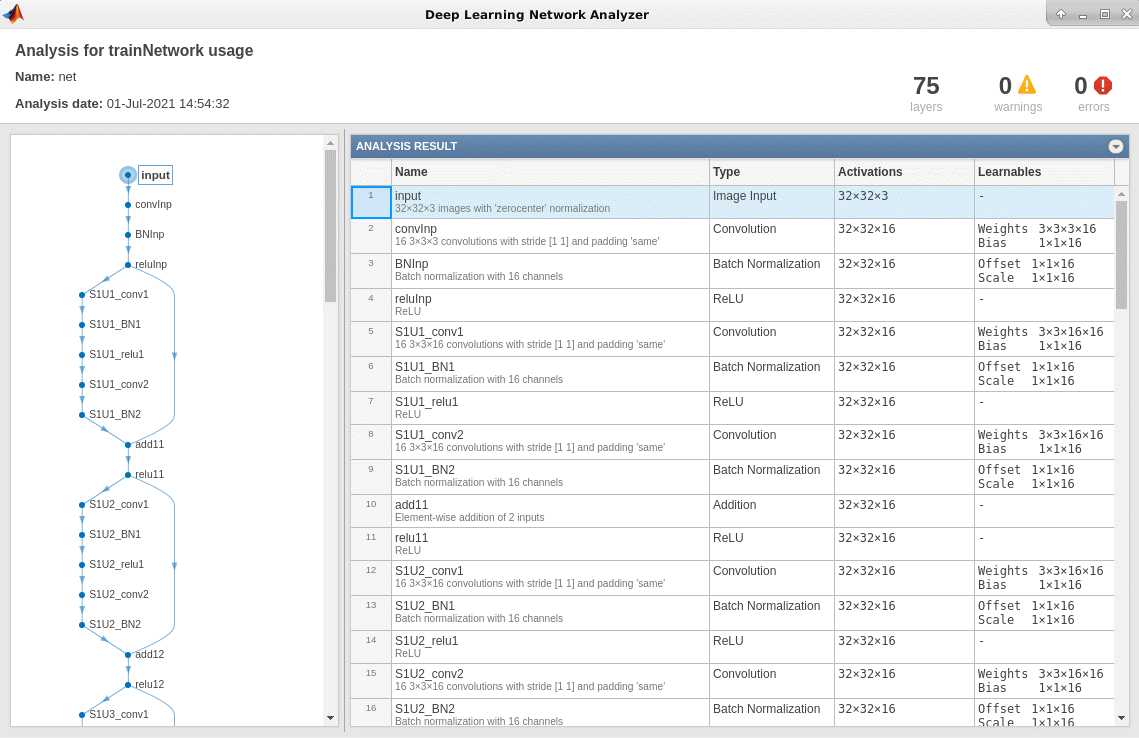
You can use analyzeNetwork to analyze the deep learning network architecture.
analyzeNetwork(net)
Load Data
Download the CIFAR-10 data set [1] by executing the code below. The data set contains 60,000 images. Each image is 32-by-32 in size and has three color channels (RGB). The size of the data set is 175 MB. Depending on your internet connection, the download process can take some time.
datadir = tempdir; downloadCIFARData(datadir);
Downloading CIFAR-10 dataset (175 MB). This can take a while...done.
Prepare Data for Calibration and Validation
Load the CIFAR-10 training and test images as 4-D arrays. The training set contains 50,000 images and the test set contains 10,000 images. Use the CIFAR-10 test images for network validation.
[XTrain,YTrain,XValidation,YValidation] = loadCIFARData(datadir);
You can display a random sample of the training images using the following code.
figure;
idx = randperm(size(XTrain,4),20);
im = imtile(XTrain(:,:,:,idx),'ThumbnailSize',[96,96]);
imshow(im)
Create an augmentedImageDatastore object to use for calibration and validation. Use 200 random images for calibration and 50 random images for validation.
inputSize = net.Layers(1).InputSize; augimdsTrain = augmentedImageDatastore(inputSize,XTrain,YTrain); augimdsCalibration = shuffle(augimdsTrain).subset(1:200); augimdsValidation = augmentedImageDatastore(inputSize,XValidation,YValidation); augimdsValidation = shuffle(augimdsValidation).subset(1:50);
Quantize the Network for GPU Deployment Using the Deep Network Quantizer App
This example uses a GPU execution environment. To learn about the products required to quantize and deploy the deep learning network to a GPU environment, see Quantization Workflow System Requirements.
In the MATLAB® Command Window, open the Deep Network Quantizer app.
deepNetworkQuantizer
Select New > Quantize a network. In the dialog box, select the execution environment and the network to quantize from the base workspace. For this example, select a GPU execution environment and the dlnetwork net.

In the Calibrate section of the toolstrip, under Calibration Data, select the augmentedImageDatastore object from the base workspace containing the calibration data augimdsCalibration.
Click Calibrate.
The Deep Network Quantizer app uses the calibration data to exercise the network and collect range information for the learnable parameters in the network layers.
When the calibration is complete, the app displays a table containing the weights and biases in the convolutional, as well as fully connected layers of the network and the dynamic ranges of the activations in all layers of the network with their minimum and maximum values during the calibration. To the right of the table, the app displays histograms of the dynamic ranges of the parameters.
In the Quantize section of the toolstrip, under Quantize, select the MinMax exponent scheme. Click Quantize.
The Deep Network Quantizer quantizes the weights, activations, and biases of convolutional layers in the network to scales 8-bit integer types. The app updates the histogram of the dynamic ranges of the parameters. The gray regions of the histograms indicate data that cannot be represented by the quantized representation. For more information on how to interpret these histograms, see Data Types and Scaling for Quantization of Deep Neural Networks.
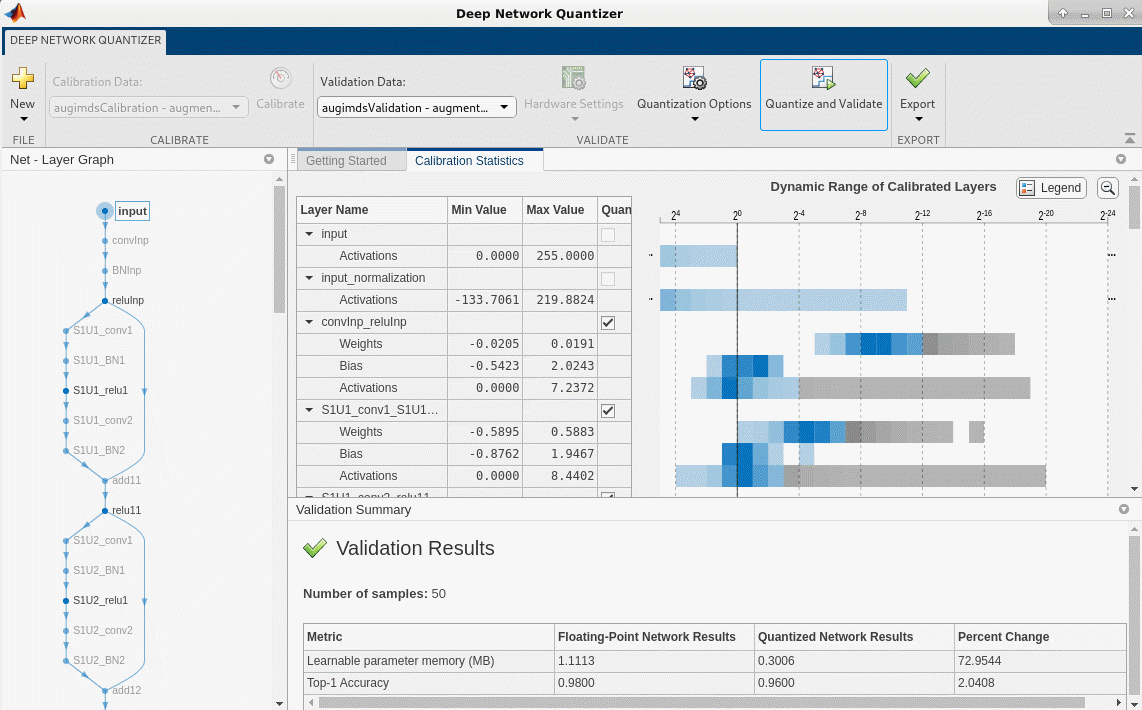
In the Quantize column of the table, indicate whether to quantize the learnable parameters in the layer. Layers that are not convolution layers cannot be quantized, and therefore cannot be selected. Layers that are not quantized remain in single precision after quantization.
In the Validate section of the toolstrip, under Validation Data, select the augmentedImageDatastore object from the base workspace containing the validation data, augimdsValidation.
In the Validate section of the toolstrip, under Validation Options, add a custom metric function to use for validation. For this example, enter the name of the custom metric function hComputeAccuracy. Select Add to add hComputeAccuracy to the list of metric functions available in the app. Select hComputeAccuracy as the metric function to use for validation. This custom metric function compares the predicted label to the ground truth and returns the top-1 accuracy. The custom metric function must be on the path.
Click Validate.
The app quantizes the network and displays a summary of the validation results. For this set of calibration and validation images, quantization of the network results in a 2% decrease in accuracy with a 73% reduction in learnable parameter memory for the set of 50 validation images.

After quantizing and validating the network, you can export the network or generate code. To export the network, select Export > Export Quantizer to create a dlquantizer object in the base workspace. To open the GPU Coder app and generate GPU code from the optimized neural network, select Export > Generate Code. To learn how to generate CUDA code for an optimized deep convolutional neural network using GPU Coder™, see Generate INT8 Code for Deep Learning Networks (GPU Coder).
Validate the Performance of the Network Using Multiple Metric Functions
You can use multiple metric functions to evaluate the performance of the network simultaneously by using the dlquantizer function.
To begin, load the pretrained network and data, and prepare the data for calibration and validation, as described above.
Create a dlquantizer object. Specify the network to quantize and the execution environment to use. Use the calibrate function to exercise the network with sample inputs from augimdsCalibration and collect range information.
dq = dlquantizer(net,'ExecutionEnvironment','GPU'); calResults = calibrate(dq,augimdsCalibration)
Specify the metric functions in a dlquantizationOptions object. Use the validate function to quantize the learnable parameters in the convolution layers of the network and exercise the network. The validate function uses the metric functions defined in the dlquantizationOptions object to compare the results of the network before and after quantization. For this example, use the top-1 accuracy and top-5 accuracy metrics are used to evaluate the performance of the network.
dqOpts = dlquantizationOptions('Target','gpu', ... 'MetricFcn',... {@(x)hComputeAccuracy(x,net,augimdsValidation), ... @(x)hComputeTop_5(x,net,augimdsValidation)}); validationResults = validate(dq,augimdsValidation,dqOpts)
validationResults = struct with fields:
NumSamples: 50
MetricResults: [1×2 struct]
Statistics: [2×2 table]
Examine the MetricResults.Result field of the validation output to see the performance of the optimized network as measured by each metric function used.
validationResults.MetricResults.Result
ans=2×2 table
'Floating-Point' 0.9800
'Quantized' 0.9600
ans=2×2 table
'Floating-Point' 1
'Quantized' 1
validationResults.Statistics
ans=2×2 table
'Floating-Point' 1111336
'Quantized' 298648
To visualize the calibration statistics, first save the dlquantizer object dq.
save('dlquantObj.mat','dq')
Then import the dlquantizer object dq in the Deep Network Quantizer app by selecting New > Import dlquantizer object.
Generate CUDA Code
Generate CUDA® code for an optimized deep convolutional neural network.
Create Entry-Point Function
Write an entry-point function in MATLAB that:
Uses the
coder.loadDeepLearningNetwork(GPU Coder) function to load a deep learning model and to construct and set up a CNN class. For more information, see Load Pretrained Networks for Code Generation (GPU Coder).Calls
predictto predict the responses.
type('mynet_predict.m');function out = mynet_predict(netFile, im)
dlIn = dlarray(im,"SSC");
persistent net;
if isempty(net)
net = coder.loadDeepLearningNetwork(netFile);
end
dlOut = predict(net,dlIn);
out = extractdata(dlOut);
end
A persistent object mynet loads the DAGNetwork object. The first call to the entry-point function constructs and sets up the persistent object. Subsequent calls to the function reuse the same object to call predict on inputs, avoiding reconstructing and reloading the network object.
Code Generation by Using codegen
To configure build settings such as the output file name, location, and type, you create coder configuration objects. To create the objects, use the coder.gpuConfig function. For example, when generating CUDA MEX using the codegen command, use cfg = coder.gpuConfig('mex').
To specify code generation parameters for cuDNN, set the DeepLearningConfig property to a coder.CuDNNConfig object that you create by using coder.DeepLearningConfig.
Specify the location of the MAT file containing the calibration data.
Specify the precision of the inference computations in supported layers by using the DataType property. For 8-bit integers, use 'int8'. Int8 precision requires a CUDA GPU with compute capability of 6.1, 6.3, or higher. Use the ComputeCapability property of the GPU code configuration object to set the appropriate compute capability value.
cfg = coder.gpuConfig('mex'); cfg.TargetLang = 'C++'; cfg.DeepLearningConfig = coder.DeepLearningConfig('cudnn'); cfg.DeepLearningConfig.DataType = 'int8'; cfg.DeepLearningConfig.CalibrationResultFile = 'dlquantObj.mat'; netFile = 'mynet.mat'; save(netFile,'net');
Run the codegen command. The codegen command generates CUDA code from the mynet_predict.m entry-point function.
codegen -config cfg mynet_predict -args {coder.Constant(netFile), ones(inputSize, 'single')} -report
When code generation is successful, you can view the resulting code generation report by clicking View Report in the MATLAB Command Window. The report is displayed in the Report Viewer window. If the code generator detects errors or warnings during code generation, the report describes the issues and provides links to the problematic MATLAB code. See Code Generation Reports (MATLAB Coder).
![]()
References
[1] Krizhevsky, Alex. 2009. "Learning Multiple Layers of Features from Tiny Images." https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf