estimate
Fit conditional variance model to data
Syntax
Description
EstMdl = estimate(Mdl,y)EstMdl. This model stores the estimated parameter values
resulting from fitting the partially specified conditional variance model
Mdl to the observed univariate time series
y by using maximum likelihood.
EstMdl and Mdl are the same model
type and have the same structure (see garch, egarch, and gjr).
EstMdl = estimate(Mdl,Tbl1)Mdl
to response variable in the input table or timetable Tbl1,
which contains time series data, and returns the fully specified, estimated
conditional variance model EstMdl.
estimate selects the response variable named in
Mdl.SeriesName or the sole variable in
Tbl1. To select a different response variable in
Tbl1 to fit the model to, use the
ResponseVariable name-value argument. (since R2023a)
[___] = estimate(___,
specifies options using one or more name-value arguments in
addition to any of the input argument combinations in previous syntaxes.
Name,Value)estimate returns the output argument combination for the
corresponding input arguments. For example, estimate(Mdl,y,Y0=y0) fits the
conditional variance model Mdl to the vector of response data
y, and specifies the vector of presample response data
y0.
Supply all input data using the same data type. Specifically:
If you specify the numeric vector
y, optional data sets must be numeric arrays and you must use the appropriate name-value argument. For example, to specify a presample, set theY0name-value argument to a numeric matrix of presample data.If you specify the table or timetable
Tbl1, optional data sets must be tables or timetables, respectively, and you must use the appropriate name-value argument. For example, to specify a presample, set thePresamplename-value argument to a table or timetable of presample data.
Examples
Fit a GARCH(1,1) model to a simulated vector of data.
Simulate 500 data points from the GARCH(1,1) model
where and
Use the default Gaussian innovation distribution for .
Mdl0 = garch(Constant=0.0001,GARCH=0.5,ARCH=0.2); rng("default") % For reproducibility [v,y] = simulate(Mdl0,500);
The output v contains simulated conditional variances. y is a column vector of simulated responses (innovations).
Specify a GARCH(1,1) model with unknown coefficients, and fit it to the series y.
Mdl = garch(1,1); EstMdl = estimate(Mdl,y)
GARCH(1,1) Conditional Variance Model (Gaussian Distribution):
Value StandardError TStatistic PValue
__________ _____________ __________ __________
Constant 9.8911e-05 3.0726e-05 3.2191 0.001286
GARCH{1} 0.45394 0.11193 4.0557 4.9985e-05
ARCH{1} 0.26374 0.056931 4.6326 3.6111e-06
EstMdl =
garch with properties:
Description: "GARCH(1,1) Conditional Variance Model (Gaussian Distribution)"
SeriesName: "Y"
Distribution: Name = "Gaussian"
P: 1
Q: 1
Constant: 9.89107e-05
GARCH: {0.453936} at lag [1]
ARCH: {0.263738} at lag [1]
Offset: 0
The result is a new garch model called EstMdl. The parameter estimates in EstMdl resemble the parameter values that generated the simulated data.
Fit an EGARCH(1,1) model to simulated data.
Simulate 500 data points from an EGARCH(1,1) model
where and
(the distribution of is Gaussian).
Mdl0 = egarch(Constant=0.001,GARCH=0.7, ... ARCH=0.5,Leverage=-0.3); rng("default") % For reproducibility [v,y] = simulate(Mdl0,500);
The output v contains simulated conditional variances. y is a column vector of simulated responses (innovations).
Specify an EGARCH(1,1) model with unknown coefficients, and fit it to the series y.
Mdl = egarch(1,1); EstMdl = estimate(Mdl,y)
EGARCH(1,1) Conditional Variance Model (Gaussian Distribution):
Value StandardError TStatistic PValue
___________ _____________ __________ __________
Constant -0.00063866 0.031698 -0.020148 0.98392
GARCH{1} 0.70506 0.067359 10.467 1.2221e-25
ARCH{1} 0.56774 0.074746 7.5956 3.063e-14
Leverage{1} -0.32116 0.053345 -6.0204 1.7399e-09
EstMdl =
egarch with properties:
Description: "EGARCH(1,1) Conditional Variance Model (Gaussian Distribution)"
SeriesName: "Y"
Distribution: Name = "Gaussian"
P: 1
Q: 1
Constant: -0.000638658
GARCH: {0.705065} at lag [1]
ARCH: {0.567741} at lag [1]
Leverage: {-0.321158} at lag [1]
Offset: 0
The result is a new egarch model called EstMdl. The parameter estimates in EstMdl resemble the parameter values that generated the simulated data.
Fit a GJR(1,1) model to simulated data.
Simulate 500 data points from a GJR(1,1) model.
where and
Use the default Gaussian innovation distribution for .
Mdl0 = gjr(Constant=0.001,GARCH=0.5, ... ARCH=0.2,Leverage=0.2); rng("default") % For reproducibility [v,y] = simulate(Mdl0,500);
The output v contains simulated conditional variances. y is a column vector of simulated responses (innovations).
Specify a GJR(1,1) model with unknown coefficients, and fit it to the series y.
Mdl = gjr(1,1); EstMdl = estimate(Mdl,y)
GJR(1,1) Conditional Variance Model (Gaussian Distribution):
Value StandardError TStatistic PValue
__________ _____________ __________ __________
Constant 0.00097382 0.00025135 3.8743 0.00010694
GARCH{1} 0.46056 0.071793 6.4151 1.4077e-10
ARCH{1} 0.24126 0.063409 3.8047 0.00014196
Leverage{1} 0.25051 0.11265 2.2237 0.026171
EstMdl =
gjr with properties:
Description: "GJR(1,1) Conditional Variance Model (Gaussian Distribution)"
SeriesName: "Y"
Distribution: Name = "Gaussian"
P: 1
Q: 1
Constant: 0.000973819
GARCH: {0.460555} at lag [1]
ARCH: {0.241256} at lag [1]
Leverage: {0.250507} at lag [1]
Offset: 0
The result is a new gjr model called EstMdl. The parameter estimates in EstMdl resemble the parameter values that generated the simulated data.
Fit a GARCH(1,1) model to the daily close NASDAQ Composite Index returns.
Load the NASDAQ data included with the toolbox. Convert the index to returns.
load Data_EquityIdx nasdaq = DataTable.NASDAQ; y = price2ret(nasdaq); T = length(y); figure plot(y) xlim([0,T]) title("NASDAQ Returns")
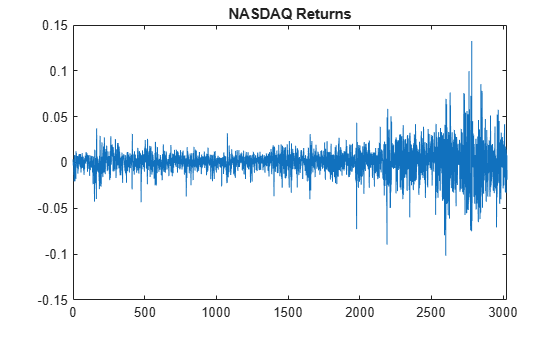
The returns exhibit volatility clustering.
Specify a GARCH(1,1) model, and fit it to the series. One presample innovation is required to initialize this model. Use the first observation of y as the necessary presample innovation.
Mdl = garch(1,1); [EstMdl,EstParamCov] = estimate(Mdl,y(2:end),E0=y(1))
GARCH(1,1) Conditional Variance Model (Gaussian Distribution):
Value StandardError TStatistic PValue
__________ _____________ __________ __________
Constant 2.0419e-06 5.4779e-07 3.7275 0.00019341
GARCH{1} 0.88074 0.0086251 102.11 0
ARCH{1} 0.11193 0.0078754 14.212 7.6833e-46
EstMdl =
garch with properties:
Description: "GARCH(1,1) Conditional Variance Model (Gaussian Distribution)"
SeriesName: "Y"
Distribution: Name = "Gaussian"
P: 1
Q: 1
Constant: 2.04187e-06
GARCH: {0.880737} at lag [1]
ARCH: {0.111927} at lag [1]
Offset: 0
EstParamCov = 3×3
10-4 ×
0.0000 -0.0000 0.0000
-0.0000 0.7439 -0.5640
0.0000 -0.5640 0.6202
The output EstMdl is a new garch model with estimated parameters.
Use the output variance-covariance matrix to calculate the estimate standard errors.
se = sqrt(diag(EstParamCov))
se = 3×1
0.0000
0.0086
0.0079
These are the standard errors shown in the estimation output display. They correspond (in order) to the constant, GARCH coefficient, and ARCH coefficient.
Fit an EGARCH(1,1) model to the daily close NASDAQ Composite Index returns.
Load the NASDAQ data included with the toolbox. Convert the index to returns.
load Data_EquityIdx nasdaq = DataTable.NASDAQ; y = price2ret(nasdaq); T = length(y); figure plot(y) xlim([0,T]) title("NASDAQ Returns")
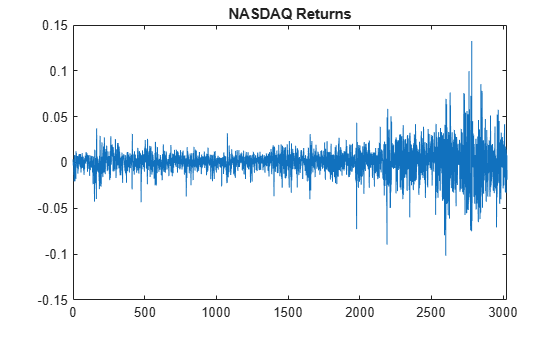
The returns exhibit volatility clustering.
Specify an EGARCH(1,1) model, and fit it to the series. One presample innovation is required to initialize this model. Use the first observation of y as the necessary presample innovation.
Mdl = egarch(1,1); [EstMdl,EstParamCov] = estimate(Mdl,y(2:end),E0=y(1))
EGARCH(1,1) Conditional Variance Model (Gaussian Distribution):
Value StandardError TStatistic PValue
_________ _____________ __________ __________
Constant -0.13478 0.022092 -6.101 1.0539e-09
GARCH{1} 0.98391 0.0024221 406.22 0
ARCH{1} 0.19964 0.013966 14.296 2.3323e-46
Leverage{1} -0.060243 0.005647 -10.668 1.4355e-26
EstMdl =
egarch with properties:
Description: "EGARCH(1,1) Conditional Variance Model (Gaussian Distribution)"
SeriesName: "Y"
Distribution: Name = "Gaussian"
P: 1
Q: 1
Constant: -0.134785
GARCH: {0.983909} at lag [1]
ARCH: {0.199645} at lag [1]
Leverage: {-0.0602432} at lag [1]
Offset: 0
EstParamCov = 4×4
10-3 ×
0.4881 0.0533 -0.1018 0.0106
0.0533 0.0059 -0.0118 0.0017
-0.1018 -0.0118 0.1950 0.0016
0.0106 0.0017 0.0016 0.0319
The output EstMdl is a new egarch model with estimated parameters.
Use the output variance-covariance matrix to calculate the estimate standard errors.
se = sqrt(diag(EstParamCov))
se = 4×1
0.0221
0.0024
0.0140
0.0056
These are the standard errors shown in the estimation output display. They correspond (in order) to the constant, GARCH coefficient, ARCH coefficient, and leverage coefficient.
Since R2023a
Fit a GARCH(1,1) model to the average weekly closing NASDAQ returns. Supply a timetable of data and specify the series for the fit.
Load the U.S. equity indices data Data_EquityIdx.mat.
load Data_EquityIdxThe timetable DataTimeTable contains the daily NASDAQ closing prices, among other indices.
Compute the weekly average closing prices of all timetable variables.
DTTW = convert2weekly(DataTimeTable,Aggregation="mean");Compute the weekly returns.
DTTRet = price2ret(DTTW); T = height(DTTRet)
T = 626
Plot the weekly NASDAQ returns.
figure
plot(DTTRet.Time,DTTRet.NASDAQ)
title("NASDAQ Weekly Returns")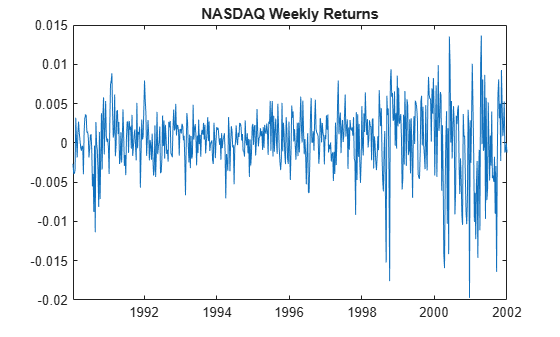
The returns exhibit volatility clustering.
When you plan to supply a timetable, you must ensure it has all the following characteristics:
The selected response variable is numeric and does not contain any missing values.
The timestamps in the
Timevariable are regular, and they are ascending or descending.
Remove all missing values from the timetable, relative to the NASDAQ returns series.
DTTRet = rmmissing(DTTRet,DataVariables="NASDAQ");
numobs = height(DTTRet)numobs = 626
Because all sample times have observed NASDAQ returns, rmmissing does not remove any observations.
Determine whether the sampling timestamps have a regular frequency and are sorted.
areTimestampsRegular = isregular(DTTRet,"weeks")areTimestampsRegular = logical
1
areTimestampsSorted = issorted(DTTRet.Time)
areTimestampsSorted = logical
1
areTimestampsRegular = 1 indicates that the timestamps of DTTRet represent a regular weekly sample. areTimestampsSorted = 1 indicates that the timestamps are sorted.
Specify a GARCH(1,1) model, and fit it to the series. Specify the entire timetable of returns and select the variable containing the NASDAQ returns.
Mdl = garch(1,1);
[EstMdl,EstParamCov] = estimate(Mdl,DTTRet,ResponseVariable="NASDAQ")
GARCH(1,1) Conditional Variance Model (Gaussian Distribution):
Value StandardError TStatistic PValue
__________ _____________ __________ __________
Constant 3.0642e-07 3.9847e-07 0.76899 0.4419
GARCH{1} 0.86476 0.01831 47.229 0
ARCH{1} 0.11873 0.019946 5.9527 2.6373e-09
EstMdl =
garch with properties:
Description: "GARCH(1,1) Conditional Variance Model (Gaussian Distribution)"
SeriesName: "Y"
Distribution: Name = "Gaussian"
P: 1
Q: 1
Constant: 3.06421e-07
GARCH: {0.864761} at lag [1]
ARCH: {0.118734} at lag [1]
Offset: 0
EstParamCov = 3×3
10-3 ×
0.0000 -0.0000 -0.0000
-0.0000 0.3352 -0.2909
-0.0000 -0.2909 0.3978
Since R2023a
Fit a GJR(1,1) model to the average weekly closing NASDAQ returns. Specify in-sample and presample data in a timetable.
Load the U.S. equity indices data Data_EquityIdx.mat.
load Data_EquityIdxThe timetable DataTimeTable contains the daily NASDAQ closing prices, among other indices.
Compute the weekly average closing prices of all timetable variables.
DTTW = convert2weekly(DataTimeTable,Aggregation="mean");Compute the weekly returns.
DTTRet = price2ret(DTTW); T = height(DTTRet)
T = 626
Plot the weekly NASDAQ returns.
figure
plot(DTTRet.Time,DTTRet.NASDAQ)
title("NASDAQ Weekly Returns")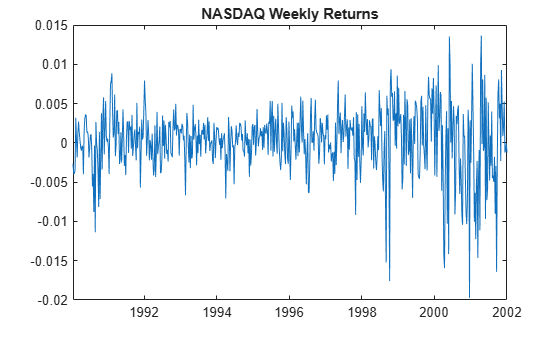
The returns exhibit volatility clustering.
When you plan to supply a timetable, you must ensure it has all the following characteristics:
The selected response variable is numeric and does not contain any missing values.
The timestamps in the
Timevariable are regular, and they are ascending or descending.
Remove all missing values from the timetable, relative to the NASDAQ returns series.
DTTRet = rmmissing(DTTRet,DataVariables="NASDAQ");
numobs = height(DTTRet)numobs = 626
Because all sample times have observed NASDAQ returns, rmmissing does not remove any observations.
Determine whether the sampling timestamps have a regular frequency and are sorted.
areTimestampsRegular = isregular(DTTRet,"weeks")areTimestampsRegular = logical
1
areTimestampsSorted = issorted(DTTRet.Time)
areTimestampsSorted = logical
1
areTimestampsRegular = 1 indicates that the timestamps of DTTRet represent a regular weekly sample. areTimestampsSorted = 1 indicates that the timestamps are sorted.
Because , one presample innovation is required to initialize this model. Partition the timetable of data into sets containing required presample and insample observations.
numpreobs = 1; DTTRetPresample = DTTRet(1:numpreobs,:); DTTRetInsample = DTTRet((numpreobs+1):end,:);
Specify a GJR(1,1) model, and fit it to the series. Specify the timetables of NASDAQ weekly returns for the required presample innovations and in-sample data.
Mdl = gjr(1,1); [EstMdl,EstParamCov] = estimate(Mdl,DTTRetInsample,Presample=DTTRetPresample, ... ResponseVariable="NASDAQ",PresampleInnovationVariable="NASDAQ");
GJR(1,1) Conditional Variance Model (Gaussian Distribution):
Value StandardError TStatistic PValue
__________ _____________ __________ ___________
Constant 7.7286e-07 5.3834e-07 1.4356 0.15111
GARCH{1} 0.77144 0.033164 23.261 1.0916e-119
ARCH{1} 0.092926 0.033666 2.7602 0.0057764
Leverage{1} 0.1922 0.050338 3.8182 0.00013442
The output EstMdl is a new gjr model with estimated parameters.
Use the output variance-covariance matrix to calculate the estimate standard errors.
se = sqrt(diag(EstParamCov))
se = 4×1
0.0000
0.0332
0.0337
0.0503
These are the standard errors shown in the estimation output display. They correspond (in order) to the constant, GARCH coefficient, ARCH coefficient, and leverage coefficient.
Input Arguments
Name-Value Arguments
Output Arguments
Tips
Algorithms
If you do not specify the presample data (
E0andV0, orPresample),estimatederives the necessary presample observations from the unconditional, or long-run, variance of the offset-adjusted response process.For all conditional variance models, presample conditional variances are the sample average of the squared disturbances of the offset-adjusted response data.
For GARCH(P,Q) and GJR(P,Q) models, presample innovations are the square root of the average squared value of the offset-adjusted response data.
For EGARCH(P,Q) models, presample innovations are
0.
These specifications minimize initial transient effects.
If you specify a value for the
Displayname-value argument, it takes precedence over the specifications of the optimization optionsDiagnosticsandDisplay. Otherwise,estimatehonors all selections related to the display of optimization information in the optimization options.
References
[1] Bollerslev, Tim. “Generalized Autoregressive Conditional Heteroskedasticity.” Journal of Econometrics 31 (April 1986): 307–27. https://doi.org/10.1016/0304-4076(86)90063-1.
[2] Bollerslev, Tim. “A Conditionally Heteroskedastic Time Series Model for Speculative Prices and Rates of Return.” The Review of Economics and Statistics 69 (August 1987): 542–47. https://doi.org/10.2307/1925546.
[3] Box, G. E. P., G. M. Jenkins, and G. C. Reinsel. Time Series Analysis: Forecasting and Control. 3rd ed. Englewood Cliffs, NJ: Prentice Hall, 1994.
[4] Enders, W. Applied Econometric Time Series. Hoboken, NJ: John Wiley & Sons, 1995.
[5] Engle, Robert. F. “Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdom Inflation.” Econometrica 50 (July 1982): 987–1007. https://doi.org/10.2307/1912773.
[6] Glosten, L. R., R. Jagannathan, and D. E. Runkle. “On the Relation between the Expected Value and the Volatility of the Nominal Excess Return on Stocks.” The Journal of Finance. Vol. 48, No. 5, 1993, pp. 1779–1801.
[7] Greene, W. H. Econometric Analysis. 3rd ed. Upper Saddle River, NJ: Prentice Hall, 1997.
[8] Hamilton, James D. Time Series Analysis. Princeton, NJ: Princeton University Press, 1994.
Version History
Introduced in R2012aSee Also
Objects
Functions
Topics
- Compare Conditional Variance Models Using Information Criteria
- Likelihood Ratio Test for Conditional Variance Models
- Estimate Conditional Mean and Variance Model
- Model Exchange Rate Volatility
- Maximum Likelihood Estimation for Conditional Variance Models
- Conditional Variance Model Estimation with Equality Constraints
- Presample Data for Conditional Variance Model Estimation
- Initial Values for Conditional Variance Model Estimation
- Optimization Settings for Conditional Variance Model Estimation