kstest
One-sample Kolmogorov-Smirnov test
Description
h = kstest(x)x comes
from a standard normal distribution, against the alternative that
it does not come from such a distribution, using the one-sample
Kolmogorov-Smirnov test. The result h is 1 if
the test rejects the null hypothesis at the 5% significance level,
or 0 otherwise.
h = kstest(x,Name,Value)
Examples
Perform the one-sample Kolmogorov-Smirnov test by using kstest. Confirm the test decision by visually comparing the empirical cumulative distribution function (cdf) to the standard normal cdf.
Load the examgrades data set. Create a vector containing the first column of the exam grade data.
load examgrades
test1 = grades(:,1);Test the null hypothesis that the data comes from a normal distribution with a mean of 75 and a standard deviation of 10. Use these parameters to center and scale each element of the data vector, because kstest tests for a standard normal distribution by default.
x = (test1-75)/10; h = kstest(x)
h = logical
0
The returned value of h = 0 indicates that kstest fails to reject the null hypothesis at the default 5% significance level.
Plot the empirical cdf and the standard normal cdf for a visual comparison.
cdfplot(x) hold on x_values = linspace(min(x),max(x)); plot(x_values,normcdf(x_values,0,1),'r-') legend('Empirical CDF','Standard Normal CDF','Location','best')
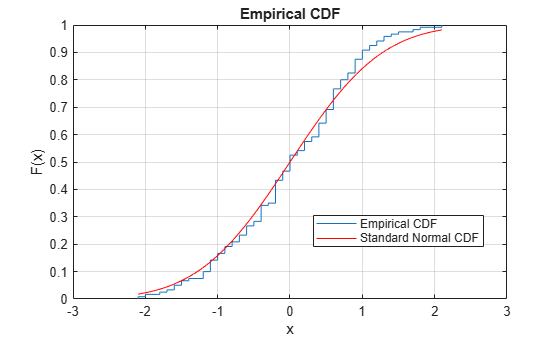
The figure shows the similarity between the empirical cdf of the centered and scaled data vector and the cdf of the standard normal distribution.
Load the sample data. Create a vector containing the first column of the students’ exam grades data.
load examgrades;
x = grades(:,1);Specify the hypothesized distribution as a two-column matrix. Column 1 contains the data vector x. Column 2 contains cdf values evaluated at each value in x for a hypothesized Student’s distribution with a location parameter of 75, a scale parameter of 10, and one degree of freedom.
test_cdf = [x,cdf('tlocationscale',x,75,10,1)];Test if the data are from the hypothesized distribution.
h = kstest(x,'CDF',test_cdf)h = logical
1
The returned value of h = 1 indicates that kstest rejects the null hypothesis at the default 5% significance level.
Load the sample data. Create a vector containing the first column of the students’ exam grades data.
load examgrades;
x = grades(:,1);Create a probability distribution object to test if the data comes from a Student’s distribution with a location parameter of 75, a scale parameter of 10, and one degree of freedom.
test_cdf = makedist('tlocationscale','mu',75,'sigma',10,'nu',1);
Test the null hypothesis that the data comes from the hypothesized distribution.
h = kstest(x,'CDF',test_cdf)h = logical
1
The returned value of h = 1 indicates that kstest rejects the null hypothesis at the default 5% significance level.
Load the sample data. Create a vector containing the first column of the students’ exam grades.
load examgrades;
x = grades(:,1);Create a probability distribution object to test if the data comes from a Student’s distribution with a location parameter of 75, a scale parameter of 10, and one degree of freedom.
test_cdf = makedist('tlocationscale','mu',75,'sigma',10,'nu',1);
Test the null hypothesis that data comes from the hypothesized distribution at the 1% significance level.
[h,p] = kstest(x,'CDF',test_cdf,'Alpha',0.01)
h = logical
1
p = 0.0021
The returned value of h = 1 indicates that kstest rejects the null hypothesis at the 1% significance level.
Load the sample data. Create a vector containing the third column of the stock return data matrix.
load stockreturns;
x = stocks(:,3);Test the null hypothesis that the data comes from a standard normal distribution, against the alternative hypothesis that the population cdf of the data is larger than the standard normal cdf.
[h,p,k,c] = kstest(x,'Tail','larger')
h = logical
1
p = 5.0854e-05
k = 0.2197
c = 0.1207
The returned value of h = 1 indicates that kstest rejects the null hypothesis in favor of the alternative hypothesis at the default 5% significance level.
Plot the empirical cdf and the standard normal cdf for a visual comparison.
[f,x_values] = ecdf(x); J = plot(x_values,f); hold on; K = plot(x_values,normcdf(x_values),'r--'); set(J,'LineWidth',2); set(K,'LineWidth',2); legend([J K],'Empirical CDF','Standard Normal CDF','Location','SE');
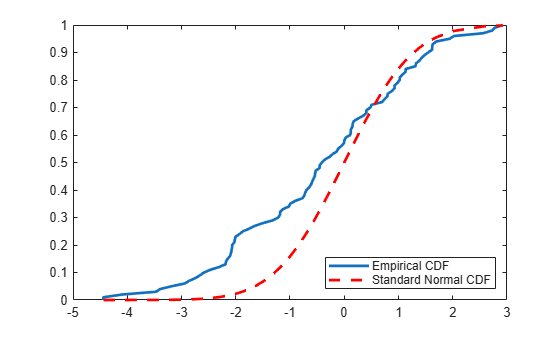
The plot shows the difference between the empirical cdf of the data vector x and the cdf of the standard normal distribution.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
kstest decides to reject the null hypothesis
by comparing the p-value p with
the significance level Alpha, not by comparing
the test statistic ksstat with the critical value cv.
Since cv is approximate, comparing ksstat with cv occasionally
leads to a different conclusion than comparing p with Alpha.
References
[1] Massey, F. J. “The Kolmogorov-Smirnov Test for Goodness of Fit.” Journal of the American Statistical Association. Vol. 46, No. 253, 1951, pp. 68–78.
[2] Miller, L. H. “Table of Percentage Points of Kolmogorov Statistics.” Journal of the American Statistical Association. Vol. 51, No. 273, 1956, pp. 111–121.
[3] Marsaglia, G., W. Tsang, and J. Wang. “Evaluating Kolmogorov’s Distribution.” Journal of Statistical Software. Vol. 8, Issue 18, 2003.
Version History
Introduced before R2006a
See Also
kstest2 | lillietest | adtest