mdwtcluster
Multisignals 1-D clustering
Description
s = mdwtcluster(x)x is
decomposed in the row direction using the discrete wavelet transform (DWT) with the Haar
wavelet and the maximum allowed level fix(log2(size(x,2))).
Note
mdwtcluster requires Statistics and Machine Learning Toolbox™.
s = mdwtcluster(___,Name,Value)'level',4 specifies the decomposition
level.
Examples
Load the 1-D multisignal elecsig10.
load elecsig10Compute the structure resulting from multisignal clustering.
lst2clu = {'s','ca1','ca3','ca6'};
S = mdwtcluster(signals,'maxclust',4,'lst2clu',lst2clu)S = struct with fields:
IdxCLU: [70×4 double]
Incons: [69×4 double]
Corr: [0.7920 0.7926 0.7947 0.7631]
Retrieve the cluster indices.
IdxCLU = S.IdxCLU;
Plot the first and third clusters.
plot(signals(IdxCLU(:,1)==1,:)','r') hold on plot(signals(IdxCLU(:,1)==3,:)','b') hold off title('Cluster 1 (Signal) and Cluster 3 (Coefficients)')
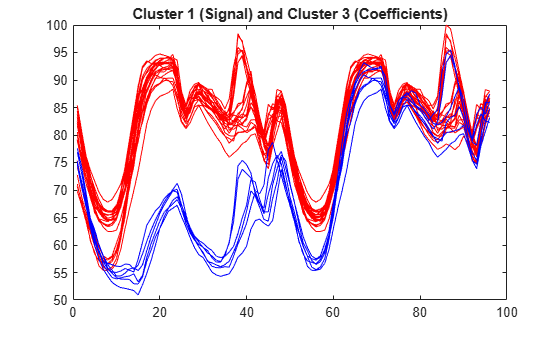
Check the equality of partitions. Confirm we obtain the same partitions using coefficients of approximation at level 3 instead of the original signals. Much less information is then used.
equalPART = isequal(IdxCLU(:,1),IdxCLU(:,3))
equalPART = logical
1
Input Arguments
Name-Value Arguments
Output Arguments
Version History
Introduced in R2008a