COVID-19 Topic Modeling and Document Summarization | Text Analytics for Biomedical Applications, Part 3
From the series: Text Analytics for Biomedical Applications
Learn how to use code for importing research articles related to COVID-19. Explore capabilities, such as topic modeling and document summarization, to gain more insight from the articles.
Published: 3 Feb 2021
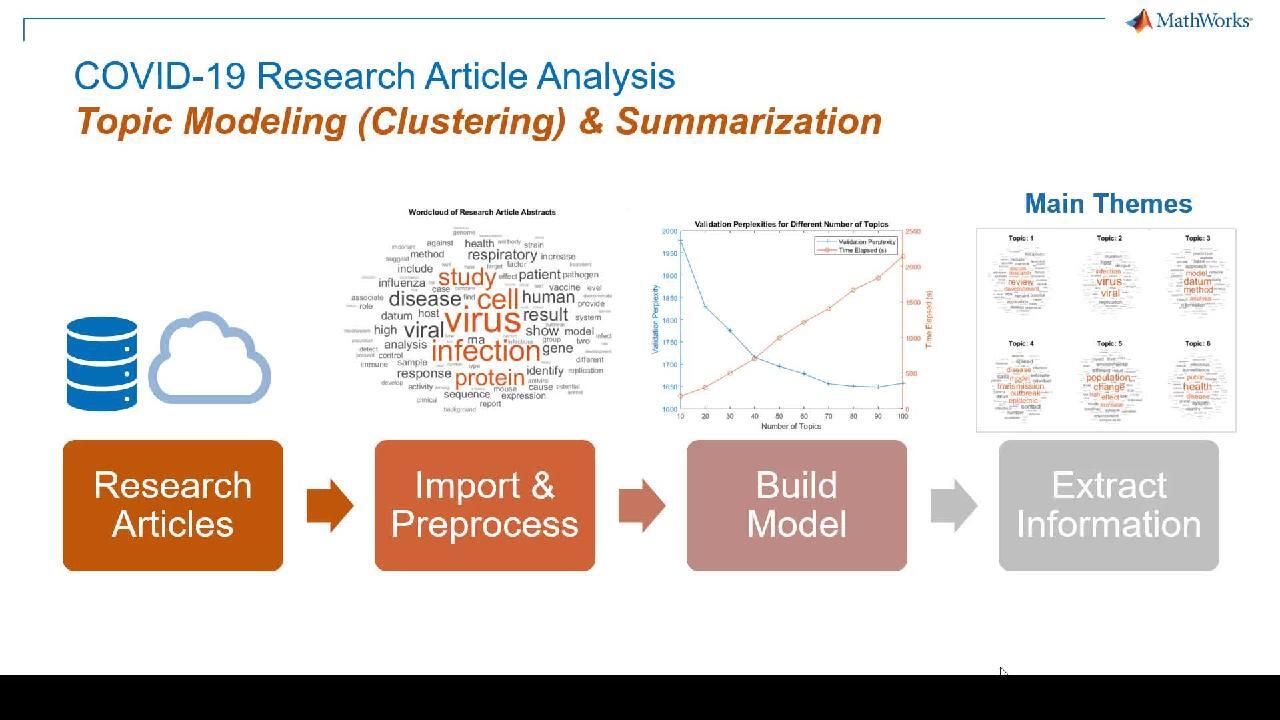
In this demo, we are going to build a model for understanding recently published COVID-19 articles using topic modeling, which is an unsupervised clustering technique, and also summarization. Topic modeling is a technique to uncover hidden patterns in the data so that we can identify the main themes of the data.
Now let's go to MATLAB and take a look at the code. This is the MATLAB Live Editor environment. In this analysis, we are going to use the data set that has about 9,000 articles and download it from Semantic Scholar.
Now, first we downloaded the articles and put it in a local folder. And then we used fileDatastore function to read the files in. This is typically used to manage a large collection of custom-format files. You can also specify custom function to read specific parts of the file. Here, we are using this function, extractPaperContents, which is a helper function that we put at the bottom of the live script that reads in the titles, abstracts, and the main body, and puts those in a table and returns that.
Once we read in the data, we explore it to try to understand how it looks like. So first, we take the titles, and preprocess those, and plot a word cloud. A word cloud is a very common way of visualizing text data. Now, the function preprocessText is another helper function. That performs common preprocessing tasks like making all the text to lowercase, making it all consistent, tokenizing it-- meaning, breaking it down into individual words and symbols, erasing punctuation, and things like that. This function is also kept at the bottom of the live script that I'll show you at the end.
Next, we do the same thing with the abstract, preprocess the text and then plot the word cloud. But the word clouds do not give us much information other than a very macro-level view of the data. So next, we then try to build a model with the abstract.
Now, before we get into the modeling, we divide the data into a training set and a test set by using cvpartition function. Here, we are using about 80% to train the data and holding out about 20% to test the data. Then we create a bag-of-words model with the training documents.
Now, a bag of words is a very simple model where we count the number of times each word appears in a document. We create an m by n matrix where m is the number of documents and n is the number of words. Now, in that m by n matrix that we create with the bagOfWords function, there may be words that appear less than two times, which are not likely to add much value to the data. So we remove those words, remove those infrequent words, and then also remove the documents that become empty as a result of removal of those words. Now we create the bag-of-words model with the validation data as well.
Next, we create the topic model. Now, topic modeling is an unsupervised clustering technique. It means that there are certain parameters that we do not know from beforehand. And they impact how the results will look like.
For example, we do not know the number of topics from beforehand. And the result may also depend on which solver we use. So we are going to first try to test the solvers. We're going to assume a number of clusters and test different solvers.
The goodness of fit of the model is estimated by a metric called validation perplexity. The lower the value, the better the model is. So we run the model with different solvers. And we compare the validation perplexity.
Now, it looks like this yellow line with the crosses were from the best. This is cvb0, which is 0-th order, collapsed variational Bayes. This one did the best. So we use the solver, and then try to test with a different number of topics, and compare the validation perplexities again.
So it looks like the validation perplexity drops pretty rapidly up to topic 40, and then it slows down. So we can assume that 40 is enough as the number of topics. Then we create the final model with 40 number of topics and cvb0 as our solver.
And just to take a look at the results, we then look at the word cloud of the first six topics. Now, just by looking at these word clouds, we can start understanding the patterns in the data. For example, topic two is about virus and infection, and then topic four is about transmission and outbreak.
So next, we are going to try to answer some of the questions. For example, we may want to know what we know about transmission. To answer that, we find the cluster that is dominantly about transmission and then find the article that has the highest probability of being in that cluster. Then we take a look at the abstract of that document. Or we could extract the top five documents and then summarize the abstracts and take a look at the summary of the abstract.
So by using topic modeling and summarization, now we narrowed down our search. We found the most important document to read and retrieved the most relevant information instead of trying to read all 9,000 articles or even 9,000 abstracts. And these are the helper functions. The first one is for extracting paper contents. And the other one is preprocessing text.
So in this demo, we went through the steps of using topic modeling and summarization to understand the articles, and uncover the hidden patterns in the data, and try to answer some questions.










Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: United States.
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)