refine
Refine initial parameters to aid state-space model estimation
Description
refine( finds
a set of initial parameter values to use when fitting the state-space
model Mdl,Y,params0)Mdl to the response data Y,
using the crude set of initial parameter values params0.
The software uses several routines, and displays the resulting loglikelihood
and initial parameter values for each routine.
refine( displays
results of the routines with additional options specified by one or
more Mdl,Y,params0,Name,Value)Name,Value pair arguments. For example,
you can include a linear regression component composed of predictors
and an initial value for the coefficients.
Output = refine(___)Output) containing a vector
of refined, initial parameter values, the loglikelihood corresponding
the initial parameter values, and the method the software used to
obtain the values. You can use any of the input arguments in the previous
syntaxes.
Examples
Suppose that a latent process is a random walk. The state equation is
where is Gaussian with mean 0 and standard deviation 1.
Generate a random series of 100 observations from , assuming that the series starts at 1.5.
T = 100;
rng(1); % For reproducibility
u = randn(T,1);
x = cumsum([1.5;u]);
x = x(2:end);Suppose further that the latent process is subject to additive measurement error. The observation equation is
where is Gaussian with mean 0 and standard deviation 1.
Use the random latent state process (x) and the observation equation to generate observations.
y = x + randn(T,1);
Together, the latent process and observation equations compose a state-space model. Assume that the state is a stationary AR(1) process. Then the state-space model to estimate is
Specify the coefficient matrices. Use NaN values for unknown parameters.
A = NaN; B = NaN; C = 1; D = NaN;
Specify the state-space model using the coefficient matrices. Specify that the initial state distribution is stationary using the StateType name-value pair argument.
StateType = 0;
Mdl = ssm(A,B,C,D,'StateType',StateType);Mdl is an ssm model. The software sets values for the initial state mean and variance. Verify that the model is specified correctly using the display in the Command Window.
Pass the observations to estimate to estimate the parameters. For the params0 parameters that are unlikely to correspond to their true values. Also, specify lower bound constraints of 0 for the standard deviations.
params0 = [-1e7 1e-6 2000];
EstMdl = estimate(Mdl,y,params0,'lb',[-Inf,0,0]);Warning: Covariance matrix of estimators cannot be computed precisely due to inversion difficulty. Check parameter identifiability. Also try different starting values and other options to compute the covariance matrix.
Method: Maximum likelihood (fmincon)
Sample size: 100
Logarithmic likelihood: -2464.23
Akaike info criterion: 4934.46
Bayesian info criterion: 4942.27
| Coeff Std Err t Stat Prob
------------------------------------------------------------
c(1) | -9.99977e+06 9.99977e+05 -10.00000 0
c(2) | 1.23086e+05 1.91161e+13 0.00000 1.00000
c(3) | 2006.86501 3.11680e+11 0.00000 1.00000
|
| Final State Std Dev t Stat Prob
x(1) | -3.37649 1999.42392 -0.00169 0.99865
estimate failed to converge, and so the results are undesirable.
Refine params0 using refine.
Output = refine(Mdl,y,params0);
logL = cell2mat({Output.LogLikelihood})';
[~,maxLogLIndx] = max(logL)maxLogLIndx = 2
refinedParams0 = Output(maxLogLIndx).Parameters
refinedParams0 = 1×3
0.9705 -0.8934 0.9330
Description = Output(maxLogLIndx).Description
Description = 'Nelder-Mead simplex'
The algorithm that yields the highest loglikelihood value is Loose bound interior point, which is the third struct in the structure array Output.
Estimate Mdl using refinedParams0, which is the vector of refined initial parameter values.
EstMdl = estimate(Mdl,y,refinedParams0,'lb',[-Inf,0,0]);Method: Maximum likelihood (fmincon)
Sample size: 100
Logarithmic likelihood: -181.379
Akaike info criterion: 368.758
Bayesian info criterion: 376.574
| Coeff Std Err t Stat Prob
---------------------------------------------------
c(1) | 0.97050 0.02863 33.90367 0
c(2) | 0.89343 0.18521 4.82401 0.00000
c(3) | 0.93303 0.15176 6.14806 0
|
| Final State Std Dev t Stat Prob
x(1) | -3.93007 0.72066 -5.45343 0
estimate converged, making the parameter estimates much more desirable. The AR model coefficient is within two standard errors of 1, which suggests that the state processes is a random walk.
Suppose that the relationship between the unemployment rate and the nominal gross national product (nGNP) is linear. Suppose further that the unemployment rate is an AR(1) series. Symbolically, and in state-space form, the model is
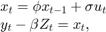
where:
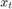 is the unemployment rate at time t.
is the unemployment rate at time t.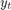 is the observed unemployment rate being deflated by the log of nGNP (
is the observed unemployment rate being deflated by the log of nGNP (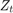 ).
).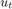 is the Gaussian series of state disturbances having mean 0 and unknown standard deviation
is the Gaussian series of state disturbances having mean 0 and unknown standard deviation  .
.
Load the Nelson-Plosser data set, which contains the unemployment rate and nGNP series data.
load Data_NelsonPlosser
Preprocess the data by taking the first difference of the unemployment rate and converting nGNP to a series of returns. Remove the observations corresponding to the sequence of NaN values at the beginning of the unemployment rate series.
isNaN = any(ismissing(DataTable),2); % Flag periods containing NaNs
gnpn = DataTable.GNPN(~isNaN);
y = DataTable.UR(~isNaN);
y = diff(y);
T = size(y,1);
Z = [ones(T,1) price2ret(gnpn)];
This example continues using the series without NaN values. However, using the Kalman filter framework, the software can accommodate series containing missing values.
Specify the coefficient matrices.
A = NaN; B = NaN; C = 1;
Specify the state-space model using ssm.
Mdl = ssm(A,B,C);
Find a good set of starting parameters to use for estimation.
params0 = [150 1000]; % Initial values chosen arbitrarily Beta0 = [1 -100]; Output = refine(Mdl,y,params0,'Predictors',Z,'Beta0',Beta0);
Output is a 1-by-5 structure array containing the recommended initial parameter values.
Choose the initial parameter values corresponding to the largest loglikelihood.
logL = cell2mat({Output.LogLikelihood})';
[~,maxLogLIndx] = max(logL)
refinedParams0 = Output(maxLogLIndx).Parameters
Description = Output(maxLogLIndx).Description
maxLogLIndx =
2
refinedParams0 =
0.0000 -1.3441 1.3477 -24.4336
Description =
'Nelder-Mead simplex'
Estimate Mdl using the refined initial parameter values refinedParams0.
EstMdl = estimate(Mdl,y,refinedParams0(1:(end - 2)),'Predictors',Z,... 'Beta0',refinedParams0((end - 1):end));
Method: Maximum likelihood (fminunc)
Sample size: 61
Logarithmic likelihood: -103.321
Akaike info criterion: 214.642
Bayesian info criterion: 223.085
| Coeff Std Err t Stat Prob
----------------------------------------------------------
c(1) | 0.20499 0.12217 1.67793 0.09336
c(2) | -1.31586 0.08283 -15.88649 0
y <- z(1) | 1.38082 0.23315 5.92241 0
y <- z(2) | -24.87986 1.76909 -14.06365 0
|
| Final State Std Dev t Stat Prob
x(1) | 1.19607 0 Inf 0
estimate returns reasonable parameter estimates and their corresponding standard errors.
Input Arguments
Name-Value Arguments
Output Arguments
Tips
Likelihood surfaces of state-space models can be complicated, for example, they might contain multiple local maxima. If
estimatefails to converge, or converges to an unsatisfactory solution, thenrefinemight find a better set of initial parameter values to pass toestimate.The refined initial parameter values returned by
refinemight appear similar to each other and toparams0. Choose a set yielding estimates that make economic sense and correspond to relatively large loglikelihood values.If a refinement attempt fails, then the software displays errors and sets the corresponding loglikelihood to
-Inf. It also sets its initial parameter values to[].
Algorithms
The Kalman filter accommodates missing data by not updating filtered state estimates corresponding to missing observations. In other words, suppose that your data has a missing observation at period t. Then, the state forecast for period t, based on the previous t – 1 observations, is equivalent to the filtered state for period t.
Version History
Introduced in R2014a