trainFromData
Syntax
Description
tfdStats = trainFromData(___,tfdOpts)rlTrainingFromDataOptions object trainFDOpts.
tfdStats = trainFromData(___,logger=lgr)FileLogger object
lgr.
Examples
To collect training data, first, create an environment.
env = rlPredefinedEnv("CartPole-Discrete");Create a built-in PPO agent with default networks.
agent1 = rlPPOAgent( ... getObservationInfo(env), ... getActionInfo(env));
Create a FileLogger object.
flgr = rlDataLogger;
To log the experiences on disk, assign an appropriate logger function to the logger object. This function is automatically called by the training loop at the end of each episode, and is defined at the end of the example.
flgr.EpisodeFinishedFcn = @myEpisodeFinishedFcn;
Define a training option object to train agent1 for no more than 100 epochs, without visualizing any training progress.
tOpts = rlTrainingOptions(MaxEpisodes=100,Plots="none");Train agent1, logging the experience data.
train(agent1,env,tOpts,Logger=flgr);
At the end of this training, files containing experience data for each episode are saved in the logs folder.
Note that the only purpose of training agent1 is to collect experience data from the environment. Collecting experiences by simulating the environment in closed loop with a controller (using a for loop), or indeed collecting a series of observations caused by random actions, would also accomplish the same result.
To allow the trainFromData function to read the experience data stored in the logs folder, create a read function that, given a file name, returns the respective experience structure. For this example, the myReadFcn function is defined at the end of the example.
Check that the function can successfully retrieve data from an episode.
cd logs exp = myReadFcn("loggedData002")
exp=22×1 struct array with fields:
NextObservation
Observation
Action
Reward
IsDone
size(cell2mat([exp.Action]))
ans = 1×2
1 22
cd ..Create a FileDataStore object using fileDatastore. Pass as arguments the name of the folder where files are stored and the read function. The read function is called automatically when the datastore is accessed for reading and is defined at the end of the example.
fds = fileDatastore("./logs", "ReadFcn", @myReadFcn);
Create a built-in DQN agent with default networks to be trained from the collected dataset.
agent2 = rlDQNAgent( ... getObservationInfo(env), ... getActionInfo(env));
Define an options object to train agent2 from data for 50 epochs. Each epoch contains 100 learning steps.
tfdOpts = rlTrainingFromDataOptions(MaxEpochs=50, NumStepsPerEpoch=100);
To train agent2 from data, use trainFromData. Pass the fileDataStore object fds as second input argument.
trainFromData(agent2,fds,tfdOpts);
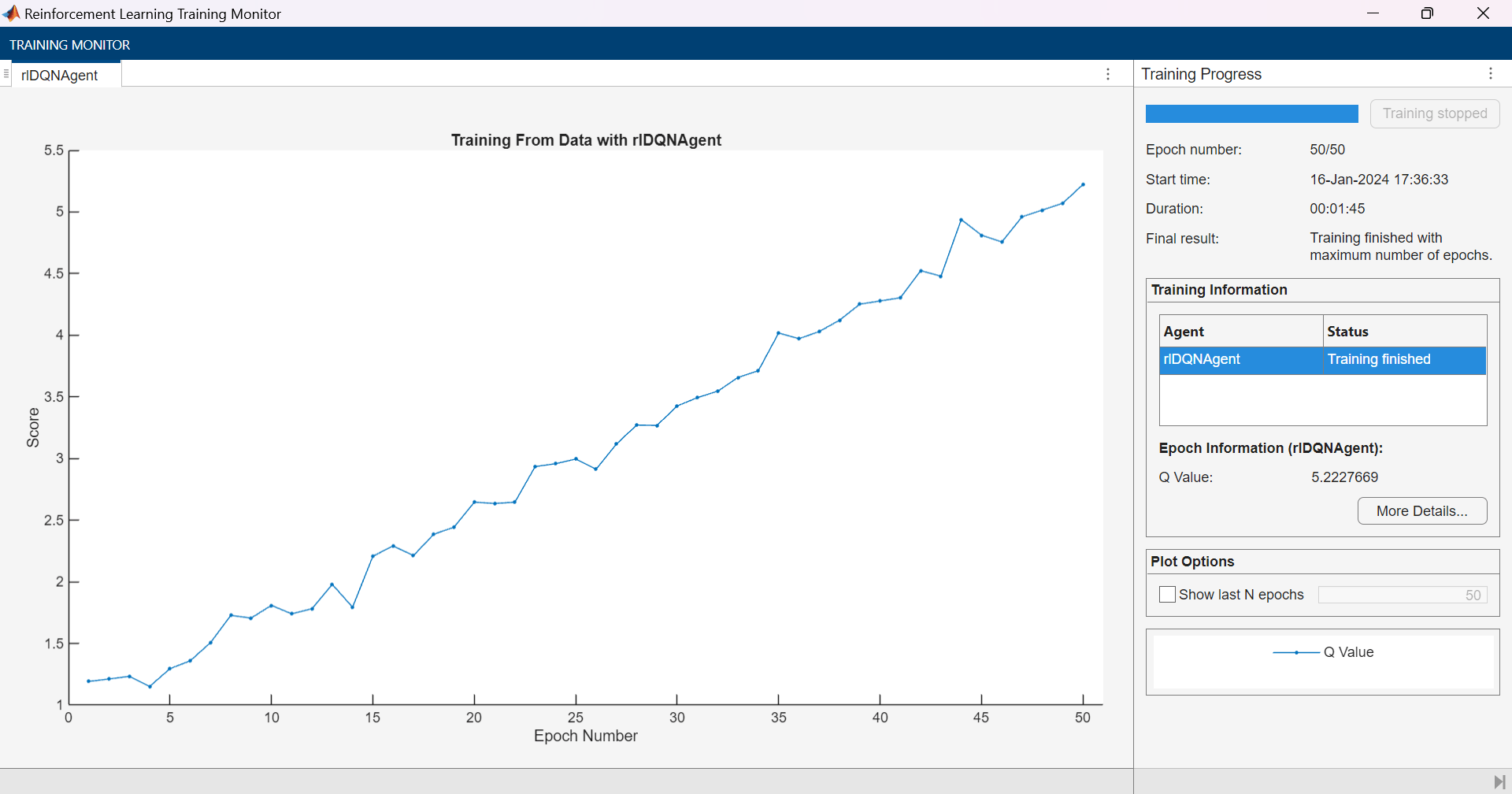
Here, the estimated Q-value seems to grow indefinitely over time. This often happens during offline training because the agent updates its estimated Q-value based on the current estimated Q-value, without using any environment feedback. To prevent the Q-value from becoming increasingly large (and inaccurate) over time, stop the training earlier or use data regularizer options such as rlConservativeQLearningOptions (for DQN or SAC agents) or rlBehaviorCloningRegularizerOptions (for DDPG, TD3 or SAC agents).
In general, the Q-value calculated as above for an agent trained offline is not necessarily indicative of the performance of the agent within an environment. Therefore, best practice is to validate the agent within an environment after offline training.
Support Functions
The data logging function. This function is automatically called by the training loop at the end of each episode, and must return a structure containing the data to log, such as experiences, simulation information, or initial observations. Here, data is a structure that contains the following fields:
EpisodeCount — current episode number
Environment — environment object
Agent — agent object
Experience — structure array containing the experiences. Each element of this array corresponds to a step and is a structure containing the fields
NextObservation,Observation,Action,RewardandIsDone.Agent — agent object
EpisodeInfo — structure containing the fields CumulativeReward, StepsTaken and InitialObservation.
SimulationInfo — contains simulation information from the episode. For MATLAB® environments this is a structure with the field SimulationError, and for Simulink® environments it is a Simulink.SimulationOutput object.
function dataToLog = myEpisodeFinishedFcn(data) dataToLog.Experience = data.Experience; end
For more information on logging data on disk, see FileLogger.
The data store read function. This function is automatically called by the training loop when the data store is accessed for reading. It must take a filename and return the experience structure array. Each element of this array corresponds to a step and is a structure containing the fields NextObservation, Observation, Action, Reward and IsDone.
function experiences = myReadFcn(fileName) if contains(fileName,"loggedData") data = load(fileName); experiences = data.episodeData.Experience{1}; else experiences = []; end end
Input Arguments
Output Arguments
Version History
Introduced in R2023a