margin
Classification margins for Gaussian kernel classification model
Description
m = margin(Mdl,Tbl,ResponseVarName)Mdl using the predictor data in table
Tbl and the class labels in
Tbl.ResponseVarName.
Examples
Load the ionosphere data set. This data set has 34 predictors and 351 binary responses for radar returns, either bad ('b') or good ('g').
load ionospherePartition the data set into training and test sets. Specify a 30% holdout sample for the test set.
rng('default') % For reproducibility Partition = cvpartition(Y,'Holdout',0.30); trainingInds = training(Partition); % Indices for the training set testInds = test(Partition); % Indices for the test set
Train a binary kernel classification model using the training set.
Mdl = fitckernel(X(trainingInds,:),Y(trainingInds));
Estimate the training-set margins and test-set margins.
mTrain = margin(Mdl,X(trainingInds,:),Y(trainingInds)); mTest = margin(Mdl,X(testInds,:),Y(testInds));
Plot both sets of margins using box plots.
boxplot([mTrain; mTest],[zeros(size(mTrain,1),1); ones(size(mTest,1),1)], ... 'Labels',{'Training set','Test set'}); title('Training-Set and Test-Set Margins')
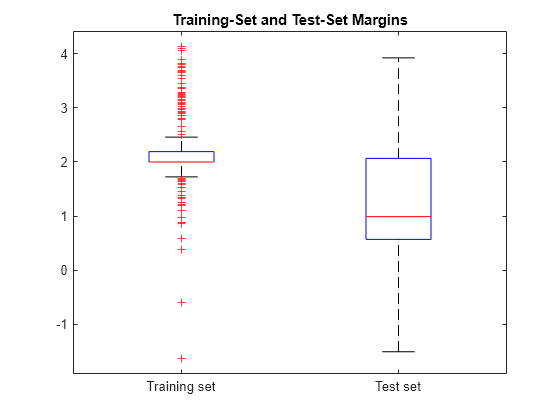
The margin distribution of the training set is situated higher than the margin distribution of the test set.
Perform feature selection by comparing test-set margins from multiple models. Based solely on this criterion, the classifier with the larger margins is the better classifier.
Load the ionosphere data set. This data set has 34 predictors and 351 binary responses for radar returns, either bad ('b') or good ('g').
load ionospherePartition the data set into training and test sets. Specify a 15% holdout sample for the test set.
rng('default') % For reproducibility Partition = cvpartition(Y,'Holdout',0.15); trainingInds = training(Partition); % Indices for the training set XTrain = X(trainingInds,:); YTrain = Y(trainingInds); testInds = test(Partition); % Indices for the test set XTest = X(testInds,:); YTest = Y(testInds);
Randomly choose 10% of the predictor variables.
p = size(X,2); % Number of predictors
idxPart = randsample(p,ceil(0.1*p));Train two binary kernel classification models: one that uses all of the predictors, and one that uses the random 10%.
Mdl = fitckernel(XTrain,YTrain); PMdl = fitckernel(XTrain(:,idxPart),YTrain);
Mdl and PMdl are ClassificationKernel models.
Estimate the test-set margins for each classifier.
fullMargins = margin(Mdl,XTest,YTest); partMargins = margin(PMdl,XTest(:,idxPart),YTest);
Plot the distribution of the margin sets using box plots.
boxplot([fullMargins partMargins], ... 'Labels',{'All Predictors','10% of the Predictors'}); title('Test-Set Margins')
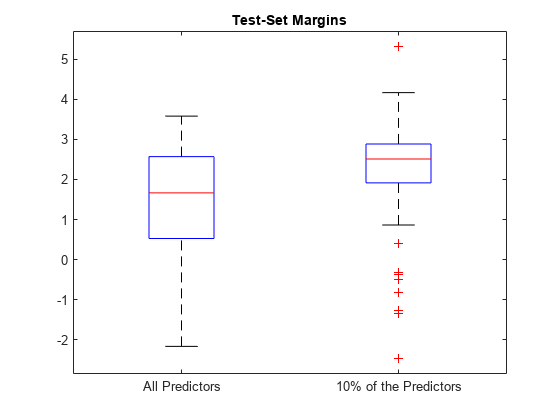
The margin distribution of PMdl is situated higher than the margin distribution of Mdl. Therefore, the PMdl model is the better classifier.