predict
Label new data using semi-supervised graph-based classifier
Description
Examples
Use both labeled and unlabeled data to train a SemiSupervisedGraphModel object. Label new data using the trained model.
Randomly generate 15 observations of labeled data, with 5 observations in each of three classes.
rng('default') % For reproducibility labeledX = [randn(5,2)*0.25 + ones(5,2); randn(5,2)*0.25 - ones(5,2); randn(5,2)*0.5]; Y = [ones(5,1); ones(5,1)*2; ones(5,1)*3];
Randomly generate 300 additional observations of unlabeled data, with 100 observations per class.
unlabeledX = [randn(100,2)*0.25 + ones(100,2);
randn(100,2)*0.25 - ones(100,2);
randn(100,2)*0.5];Fit labels to the unlabeled data by using a semi-supervised graph-based method. Specify label spreading as the labeling algorithm, and use an automatically selected kernel scale factor. The function fitsemigraph returns a SemiSupervisedGraphModel object whose FittedLabels property contains the fitted labels for the unlabeled data and whose LabelScores property contains the associated label scores.
Mdl = fitsemigraph(labeledX,Y,unlabeledX,'Method','labelspreading', ... 'KernelScale','auto')
Mdl =
SemiSupervisedGraphModel with properties:
FittedLabels: [300×1 double]
LabelScores: [300×3 double]
ClassNames: [1 2 3]
ResponseName: 'Y'
CategoricalPredictors: []
Method: 'labelspreading'
Properties, Methods
Randomly generate 150 observations of new data, with 50 observations per class. For the purposes of validation, keep track of the true labels for the new data.
newX = [randn(50,2)*0.25 + ones(50,2);
randn(50,2)*0.25 - ones(50,2);
randn(50,2)*0.5];
trueLabels = [ones(50,1); ones(50,1)*2; ones(50,1)*3];Predict the labels for the new data by using the predict function of the SemiSupervisedGraphModel object. Compare the true labels to the predicted labels by using a confusion matrix.
predictedLabels = predict(Mdl,newX); confusionchart(trueLabels,predictedLabels)
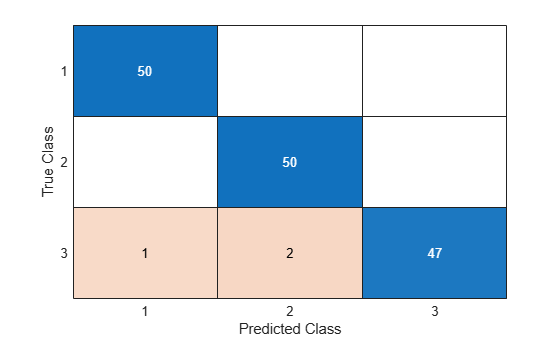
Only 3 of the 150 observations in newX are mislabeled.
Input Arguments
Output Arguments
More About
Algorithms
To fit labels to unlabeled training data, fitsemigraph
constructs a similarity graph with both labeled and unlabeled observations as nodes, and
distributes the label information from labeled observations to unlabeled observations by using
either label propagation or label spreading. The resulting
SemiSupervisedGraphModel object stores the fitted labels and label scores
for the unlabeled data in its FittedLabels and
LabelScores
properties, respectively.
To predict the label of a new observation x, the
predict function uses a weighted average of neighboring observation
scores to compute the label scores for x, namely .
n is the number of observations in the training data.
Fxj is the row vector of label scores for the training observation xj (or node j). For more information on the computation of label scores for training observations, see Algorithms.
S(x,xj) is the pairwise similarity between the new observation x and the training observation xj, where S(xi,xj) = Si,j is as defined in Similarity Graph.
The column with the maximum score in Fx corresponds to the predicted class label for x. For more information, see [1].
References
[1] Delalleau, Olivier, Yoshua Bengio, and Nicolas Le Roux. “Efficient Non-Parametric Function Induction in Semi-Supervised Learning.” Proceedings of the Tenth International Workshop on Artificial Intelligence and Statistics. 2005.
Version History
Introduced in R2020b