Building a Cloud-Based Digital Twin for an EV Battery Pack
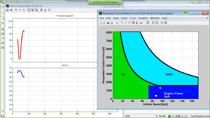
Creating, validating, and correlating the model of a physical asset is important to building a digital twin, but modeling is only one aspect of the overall process of developing and deploying digital twins. In this presentation, we showcase a project from developing the model of an EV battery, deploying it to the cloud and connecting it to the data infrastructure, and predicting battery state of health based on data from a real-world electric vehicle fleet. Join us to learn about key considerations when planning your digital twin project.
Published: 21 May 2023
Featured Product